+ ![]() +
+
+ +
+ ![]() +
+
+ +
 +
+> **Notes:**
+> - The EN, ZH metrics are the end2end evaluation results of [OmniDocBench](https://github.com/opendatalab/OmniDocBench), and Multilingual metric is the end2end evaluation results of dots.ocr-bench.
+
+
+## News
+* ```2025.07.30 ``` 🚀 We release [dots.ocr](https://github.com/rednote-hilab/dots.ocr), — a multilingual documents parsing model based on 1.7b llm, with SOTA performance.
+
+
+
+## Benchmark Results
+
+### 1. OmniDocBench
+
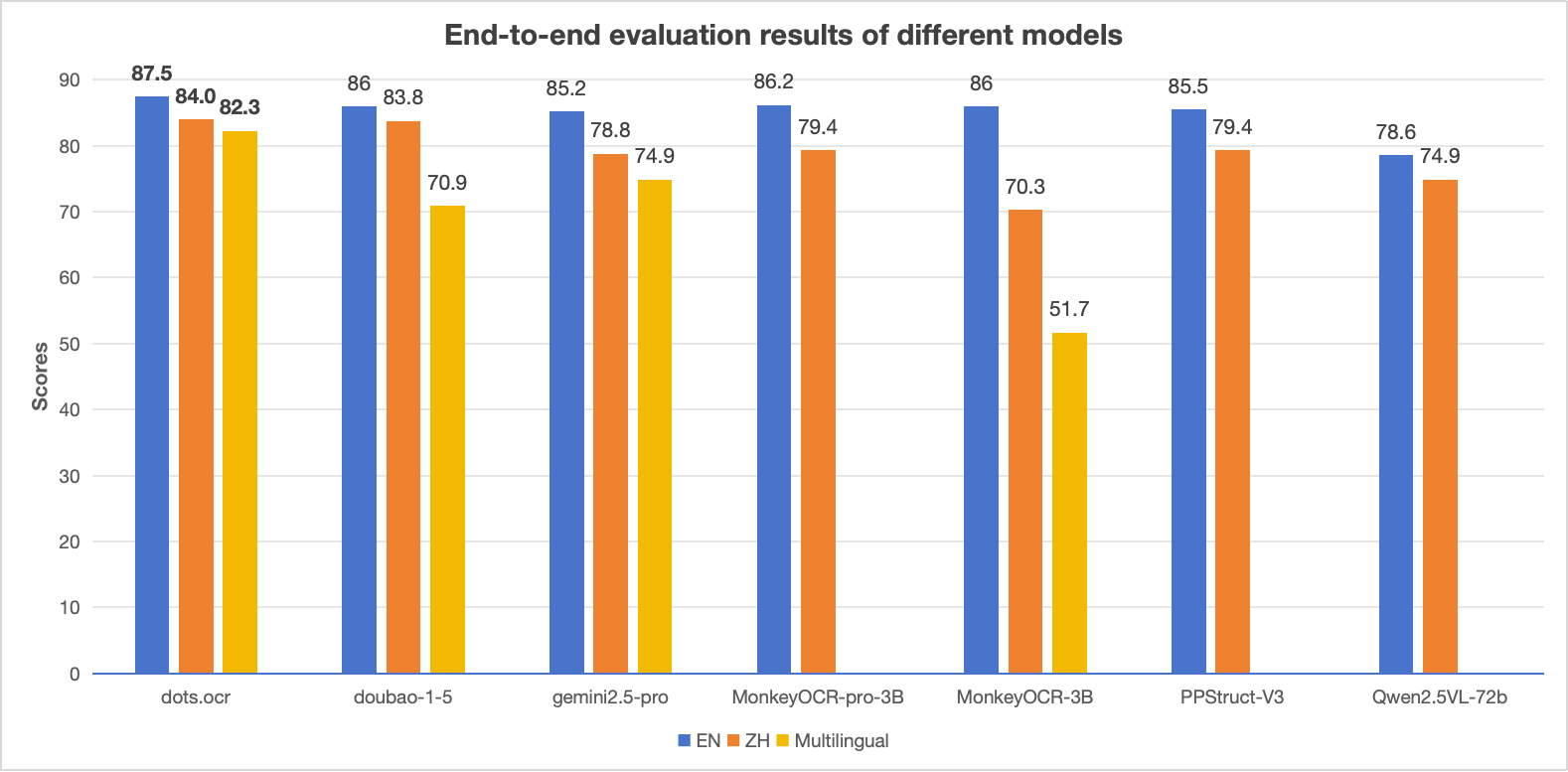
+#### The end-to-end evaluation results of different tasks.
+
+
+
+> **Notes:**
+> - The EN, ZH metrics are the end2end evaluation results of [OmniDocBench](https://github.com/opendatalab/OmniDocBench), and Multilingual metric is the end2end evaluation results of dots.ocr-bench.
+
+
+## News
+* ```2025.07.30 ``` 🚀 We release [dots.ocr](https://github.com/rednote-hilab/dots.ocr), — a multilingual documents parsing model based on 1.7b llm, with SOTA performance.
+
+
+
+## Benchmark Results
+
+### 1. OmniDocBench
+
+#### The end-to-end evaluation results of different tasks.
+
+| Model Type |
+Methods | +OverallEdit↓ | +TextEdit↓ | +FormulaEdit↓ | +TableTEDS↑ | +TableEdit↓ | +Read OrderEdit↓ | +||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | +ZH | +EN | +ZH | +EN | +ZH | +EN | +ZH | +EN | +ZH | +EN | +ZH | +||
| Pipeline Tools |
+MinerU | +0.150 | +0.357 | +0.061 | +0.215 | +0.278 | +0.577 | +78.6 | +62.1 | +0.180 | +0.344 | +0.079 | +0.292 | +
| Marker | +0.336 | +0.556 | +0.080 | +0.315 | +0.530 | +0.883 | +67.6 | +49.2 | +0.619 | +0.685 | +0.114 | +0.340 | +|
| Mathpix | +0.191 | +0.365 | +0.105 | +0.384 | +0.306 | +0.454 | +77.0 | +67.1 | +0.243 | +0.320 | +0.108 | +0.304 | +|
| Docling | +0.589 | +0.909 | +0.416 | +0.987 | +0.999 | +1 | +61.3 | +25.0 | +0.627 | +0.810 | +0.313 | +0.837 | +|
| Pix2Text | +0.320 | +0.528 | +0.138 | +0.356 | +0.276 | +0.611 | +73.6 | +66.2 | +0.584 | +0.645 | +0.281 | +0.499 | +|
| Unstructured | +0.586 | +0.716 | +0.198 | +0.481 | +0.999 | +1 | +0 | +0.06 | +1 | +0.998 | +0.145 | +0.387 | +|
| OpenParse | +0.646 | +0.814 | +0.681 | +0.974 | +0.996 | +1 | +64.8 | +27.5 | +0.284 | +0.639 | +0.595 | +0.641 | +|
| PPStruct-V3 | +0.145 | +0.206 | +0.058 | +0.088 | +0.295 | +0.535 | +- | +- | +0.159 | +0.109 | +0.069 | +0.091 | +|
| Expert VLMs |
+GOT-OCR | +0.287 | +0.411 | +0.189 | +0.315 | +0.360 | +0.528 | +53.2 | +47.2 | +0.459 | +0.520 | +0.141 | +0.280 | +
| Nougat | +0.452 | +0.973 | +0.365 | +0.998 | +0.488 | +0.941 | +39.9 | +0 | +0.572 | +1.000 | +0.382 | +0.954 | +|
| Mistral OCR | +0.268 | +0.439 | +0.072 | +0.325 | +0.318 | +0.495 | +75.8 | +63.6 | +0.600 | +0.650 | +0.083 | +0.284 | +|
| OLMOCR-sglang | +0.326 | +0.469 | +0.097 | +0.293 | +0.455 | +0.655 | +68.1 | +61.3 | +0.608 | +0.652 | +0.145 | +0.277 | +|
| SmolDocling-256M | +0.493 | +0.816 | +0.262 | +0.838 | +0.753 | +0.997 | +44.9 | +16.5 | +0.729 | +0.907 | +0.227 | +0.522 | +|
| Dolphin | +0.206 | +0.306 | +0.107 | +0.197 | +0.447 | +0.580 | +77.3 | +67.2 | +0.180 | +0.285 | +0.091 | +0.162 | +|
| MinerU 2 | +0.139 | +0.240 | +0.047 | +0.109 | +0.297 | +0.536 | +82.5 | +79.0 | +0.141 | +0.195 | +0.069< | +0.118 | +|
| OCRFlux | +0.195 | +0.281 | +0.064 | +0.183 | +0.379 | +0.613 | +71.6 | +81.3 | +0.253 | +0.139 | +0.086 | +0.187 | +|
| MonkeyOCR-pro-3B | +0.138 | +0.206 | +0.067 | +0.107 | +0.246 | +0.421 | +81.5 | +87.5 | +0.139 | +0.111 | +0.100 | +0.185 | +|
| General VLMs |
+GPT4o | +0.233 | +0.399 | +0.144 | +0.409 | +0.425 | +0.606 | +72.0 | +62.9 | +0.234 | +0.329 | +0.128 | +0.251 | +
| Qwen2-VL-72B | +0.252 | +0.327 | +0.096 | +0.218 | +0.404 | +0.487 | +76.8 | +76.4 | +0.387 | +0.408 | +0.119 | +0.193 | +|
| Qwen2.5-VL-72B | +0.214 | +0.261 | +0.092 | +0.18 | +0.315 | +0.434 | +82.9 | +83.9 | +0.341 | +0.262 | +0.106 | +0.168 | +|
| Gemini2.5-Pro | +0.148 | +0.212 | +0.055 | +0.168 | +0.356 | +0.439 | +85.8 | +86.4 | +0.13 | +0.119 | +0.049 | +0.121 | +|
| doubao-1-5-thinking-vision-pro-250428 | +0.140 | +0.162 | +0.043 | +0.085 | +0.295 | +0.384 | +83.3 | +89.3 | +0.165 | +0.085 | +0.058 | +0.094 | +|
| Expert VLMs | +dots.ocr | +0.125 | +0.160 | +0.032 | +0.066 | +0.329 | +0.416 | +88.6 | +89.0 | +0.099 | +0.092 | +0.040 | +0.067 | +
| Model Type |
+Models | +Book | +Slides | +Financial Report |
+Textbook | +Exam Paper |
+Magazine | +Academic Papers |
+Notes | +Newspaper | +Overall | +
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pipeline Tools |
+MinerU | +0.055 | +0.124 | +0.033 | +0.102 | +0.159 | +0.072 | +0.025 | +0.984 | +0.171 | +0.206 | +
| Marker | +0.074 | +0.340 | +0.089 | +0.319 | +0.452 | +0.153 | +0.059 | +0.651 | +0.192 | +0.274 | +|
| Mathpix | +0.131 | +0.220 | +0.202 | +0.216 | +0.278 | +0.147 | +0.091 | +0.634 | +0.690 | +0.300 | +|
| Expert VLMs |
+GOT-OCR | +0.111 | +0.222 | +0.067 | +0.132 | +0.204 | +0.198 | +0.179 | +0.388 | +0.771 | +0.267 | +
| Nougat | +0.734 | +0.958 | +1.000 | +0.820 | +0.930 | +0.830 | +0.214 | +0.991 | +0.871 | +0.806 | +|
| Dolphin | +0.091 | +0.131 | +0.057 | +0.146 | +0.231 | +0.121 | +0.074 | +0.363 | +0.307 | +0.177 | +|
| OCRFlux | +0.068 | +0.125 | +0.092 | +0.102 | +0.119 | +0.083 | +0.047 | +0.223 | +0.536 | +0.149 | +|
| MonkeyOCR-pro-3B | +0.084 | +0.129 | +0.060 | +0.090 | +0.107 | +0.073 | +0.050 | +0.171 | +0.107 | +0.100 | +|
| General VLMs |
+GPT4o | +0.157 | +0.163 | +0.348 | +0.187 | +0.281 | +0.173 | +0.146 | +0.607 | +0.751 | +0.316 | +
| Qwen2.5-VL-7B | +0.148 | +0.053 | +0.111 | +0.137 | +0.189 | +0.117 | +0.134 | +0.204 | +0.706 | +0.205 | +|
| InternVL3-8B | +0.163 | +0.056 | +0.107 | +0.109 | +0.129 | +0.100 | +0.159 | +0.150 | +0.681 | +0.188 | +|
| doubao-1-5-thinking-vision-pro-250428 | +0.048 | +0.048 | +0.024 | +0.062 | +0.085 | +0.051 | +0.039 | +0.096 | +0.181 | +0.073 | +|
| Expert VLMs | +dots.ocr | +0.031 | +0.047 | +0.011 | +0.082 | +0.079 | +0.028 | +0.029 | +0.109 | +0.056 | +0.055 | +
| Methods | +OverallEdit↓ | +TextEdit↓ | +FormulaEdit↓ | +TableTEDS↑ | +TableEdit↓ | +Read OrderEdit↓ | +MonkeyOCR-3B | +0.483 | +0.445 | +0.627 | +50.93 | +0.452 | +0.409 | + +
|---|---|---|---|---|---|---|
| doubao-1-5-thinking-vision-pro-250428 | +0.291 | +0.226 | +0.440 | +71.2 | +0.260 | +0.238 | +
| doubao-1-6 | +0.299 | +0.270 | +0.417 | +71.0 | +0.258 | +0.253 | +
| Gemini2.5-Pro | +0.251 | +0.163 | +0.402 | +77.1 | +0.236 | +0.202 | +
| dots.ocr | +0.177 | +0.075 | +0.297 | +79.2 | +0.186 | +0.152 | +
| Method | +F1@IoU=.50:.05:.95↑ | +F1@IoU=.50↑ | +||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Overall | +Text | +Formula | +Table | +Picture | +Overall | +Text | +Formula | +Table | +Picture | +DocLayout-YOLO-DocStructBench | +0.733 | +0.694 | +0.480 | +0.803 | +0.619 | +0.806 | +0.779 | +0.620 | +0.858 | +0.678 | + + +
| dots.ocr-parse all | +0.831 | +0.801 | +0.654 | +0.838 | +0.748 | +0.922 | +0.909 | +0.770 | +0.888 | +0.831 | +
| dots.ocr-detection only | +0.845 | +0.816 | +0.716 | +0.875 | +0.765 | +0.930 | +0.917 | +0.832 | +0.918 | +0.843 | +
| Model | +ArXiv | +Old Scans Math |
+Tables | +Old Scans | +Headers and Footers |
+Multi column |
+Long Tiny Text |
+Base | +Overall | +
|---|---|---|---|---|---|---|---|---|---|
| GOT OCR | +52.7 | +52.0 | +0.2 | +22.1 | +93.6 | +42.0 | +29.9 | +94.0 | +48.3 ± 1.1 | +
| Marker | +76.0 | +57.9 | +57.6 | +27.8 | +84.9 | +72.9 | +84.6 | +99.1 | +70.1 ± 1.1 | +
| MinerU | +75.4 | +47.4 | +60.9 | +17.3 | +96.6 | +59.0 | +39.1 | +96.6 | +61.5 ± 1.1 | +
| Mistral OCR | +77.2 | +67.5 | +60.6 | +29.3 | +93.6 | +71.3 | +77.1 | +99.4 | +72.0 ± 1.1 | +
| Nanonets OCR | +67.0 | +68.6 | +77.7 | +39.5 | +40.7 | +69.9 | +53.4 | +99.3 | +64.5 ± 1.1 | +
| GPT-4o (No Anchor) |
+51.5 | +75.5 | +69.1 | +40.9 | +94.2 | +68.9 | +54.1 | +96.7 | +68.9 ± 1.1 | +
| GPT-4o (Anchored) |
+53.5 | +74.5 | +70.0 | +40.7 | +93.8 | +69.3 | +60.6 | +96.8 | +69.9 ± 1.1 | +
| Gemini Flash 2 (No Anchor) |
+32.1 | +56.3 | +61.4 | +27.8 | +48.0 | +58.7 | +84.4 | +94.0 | +57.8 ± 1.1 | +
| Gemini Flash 2 (Anchored) |
+54.5 | +56.1 | +72.1 | +34.2 | +64.7 | +61.5 | +71.5 | +95.6 | +63.8 ± 1.2 | +
| Qwen 2 VL (No Anchor) |
+19.7 | +31.7 | +24.2 | +17.1 | +88.9 | +8.3 | +6.8 | +55.5 | +31.5 ± 0.9 | +
| Qwen 2.5 VL (No Anchor) |
+63.1 | +65.7 | +67.3 | +38.6 | +73.6 | +68.3 | +49.1 | +98.3 | +65.5 ± 1.2 | +
| olmOCR v0.1.75 (No Anchor) |
+71.5 | +71.4 | +71.4 | +42.8 | +94.1 | +77.7 | +71.0 | +97.8 | +74.7 ± 1.1 | +
| olmOCR v0.1.75 (Anchored) |
+74.9 | +71.2 | +71.0 | +42.2 | +94.5 | +78.3 | +73.3 | +98.3 | +75.5 ± 1.0 | +
| MonkeyOCR-pro-3B | +83.8 | +68.8 | +74.6 | +36.1 | +91.2 | +76.6 | +80.1 | +95.3 | +75.8 ± 1.0 | +
| dots.ocr | +82.1 | +64.2 | +88.3 | +40.9 | +94.1 | +82.4 | +81.2 | +99.5 | +79.1 ± 1.0 | +
如果您是本模型的贡献者,我们邀请您根据模型贡献文档,及时完善模型卡片内容。
\ No newline at end of file + +
+ +
+ +
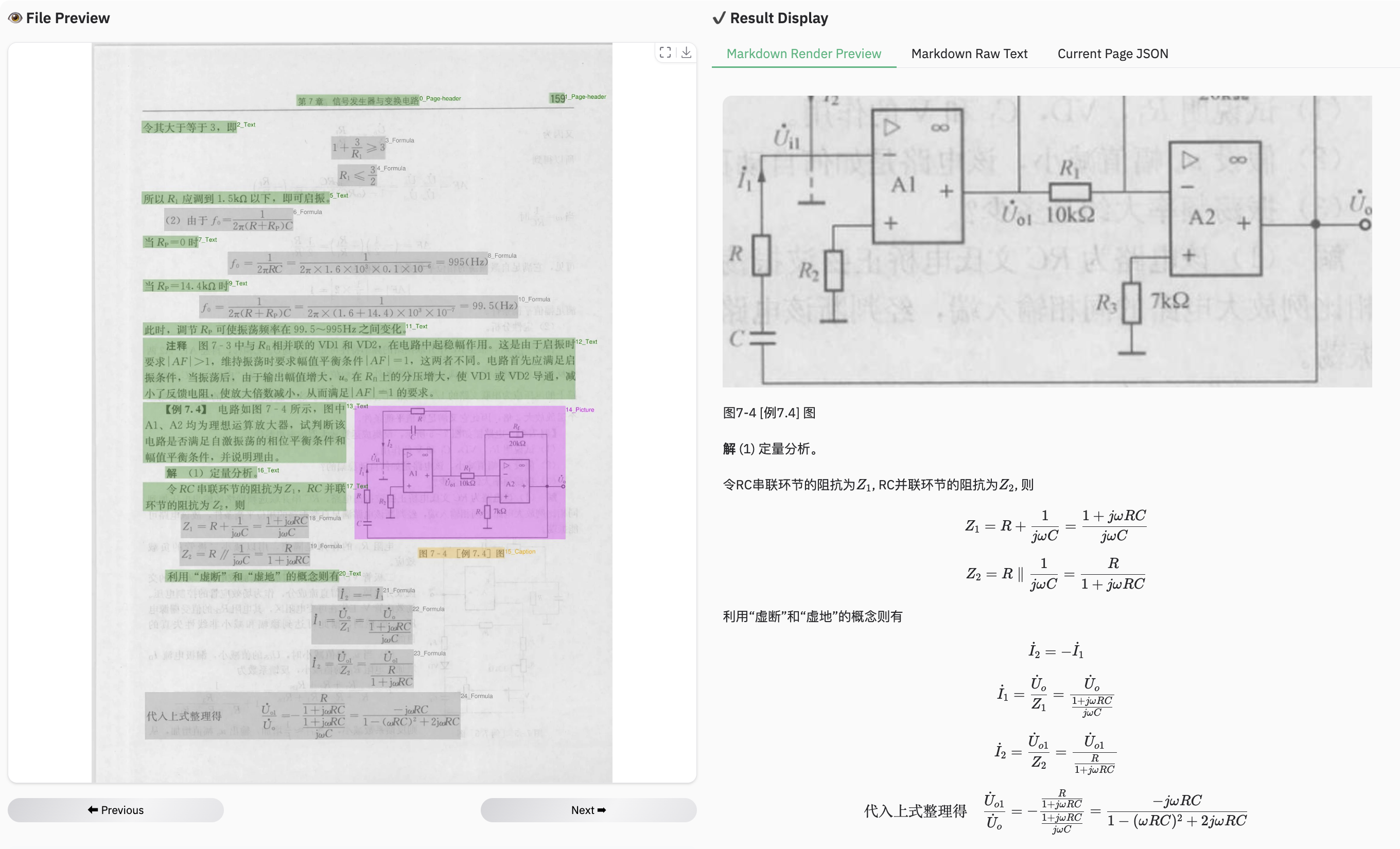
+### Example for table document
+
+
+### Example for table document
+ +
+ +
+ +
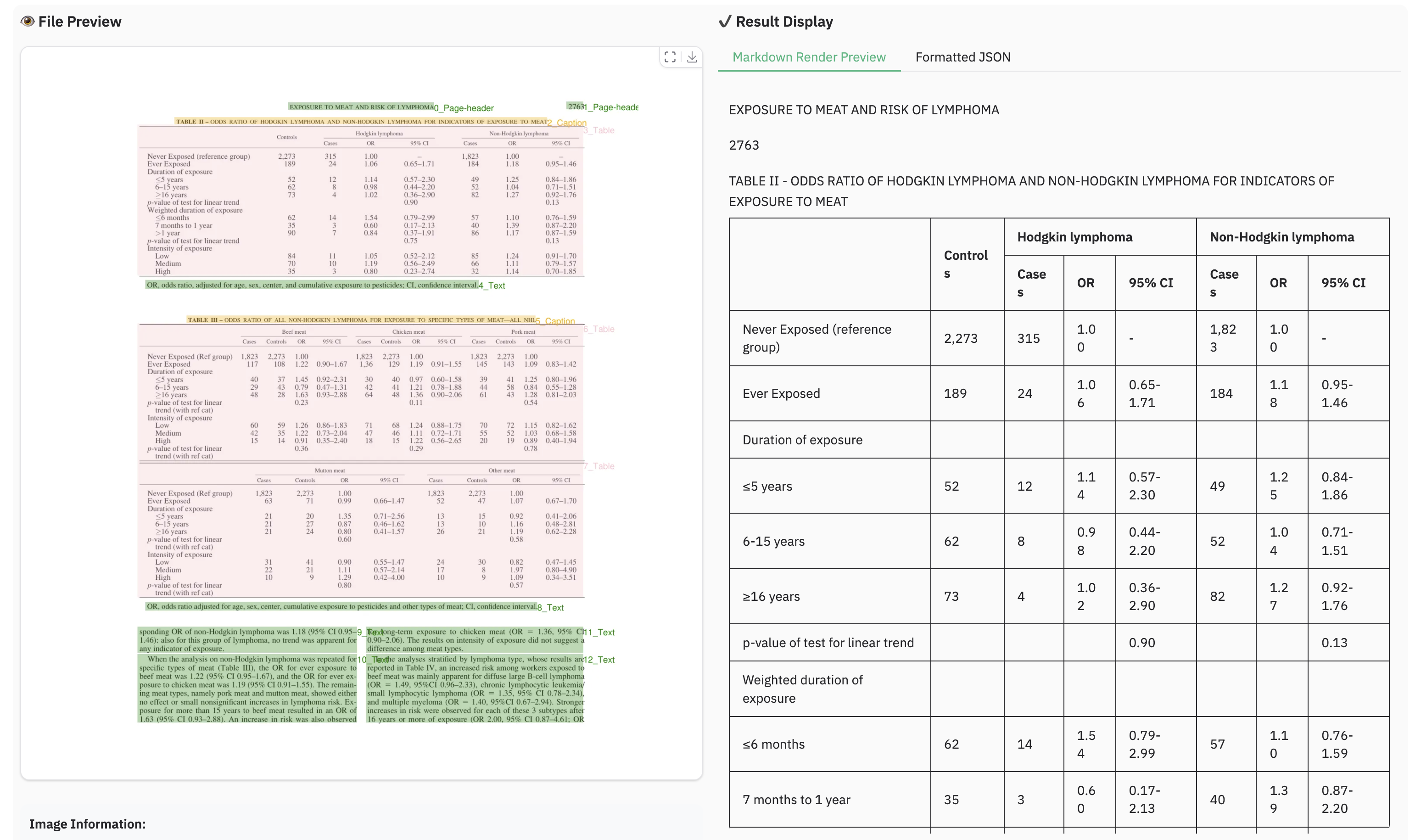
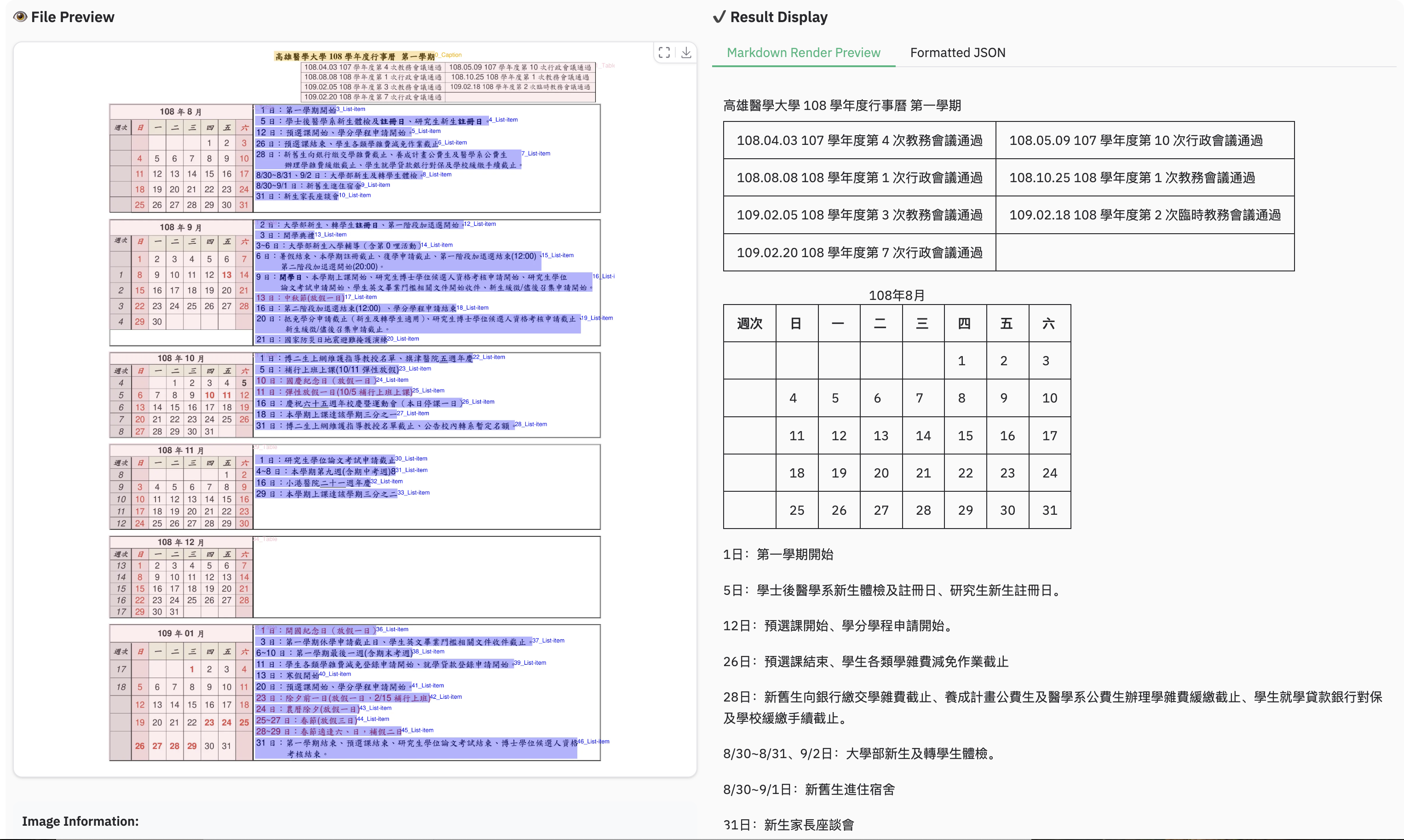
+### Example for multilingual document
+
+
+### Example for multilingual document
+ +
+ +
+ +
+ +
+ +
+### Example for reading order
+
+
+### Example for reading order
+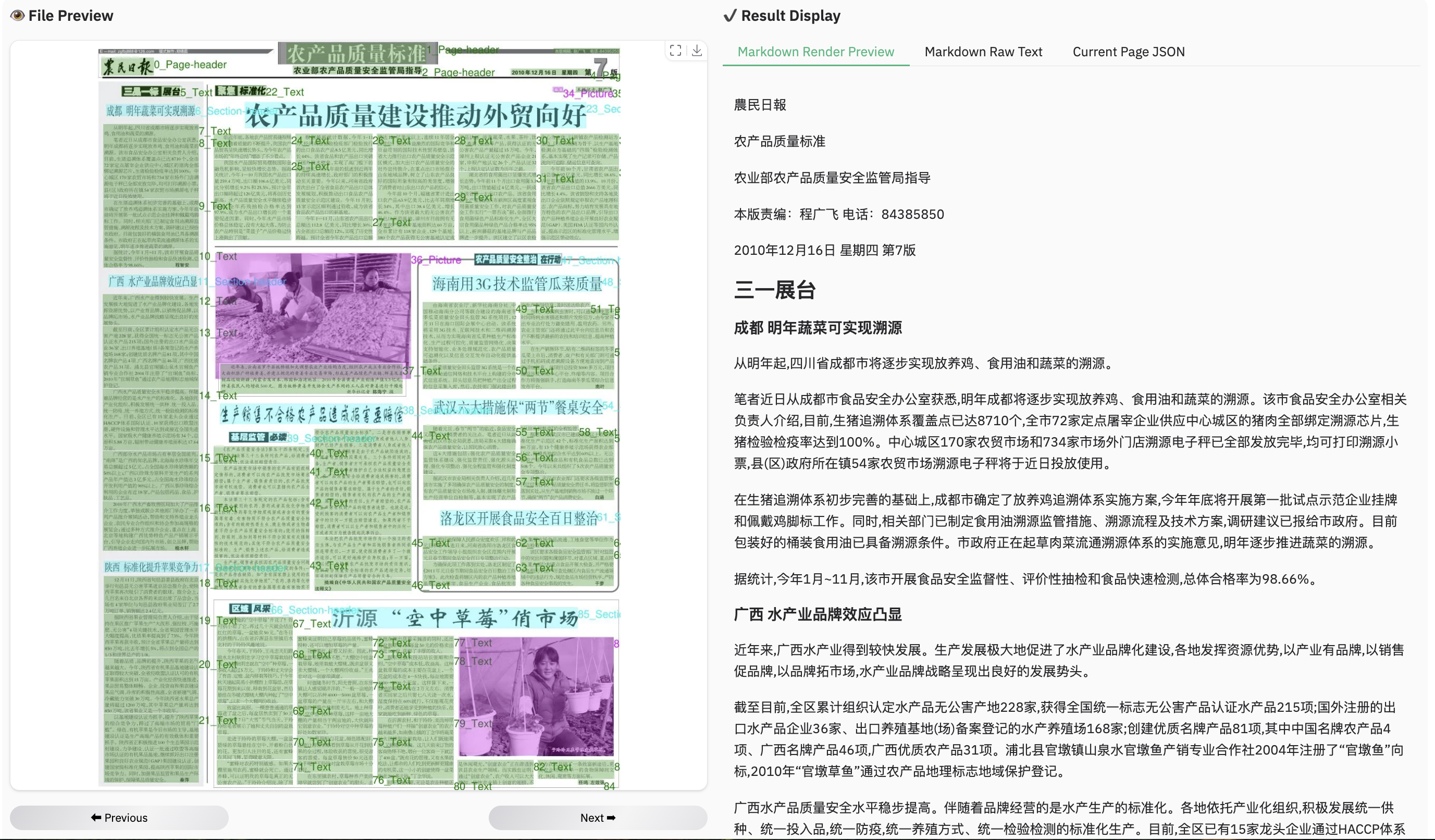 +
+### Example for grounding ocr
+
+
+### Example for grounding ocr
+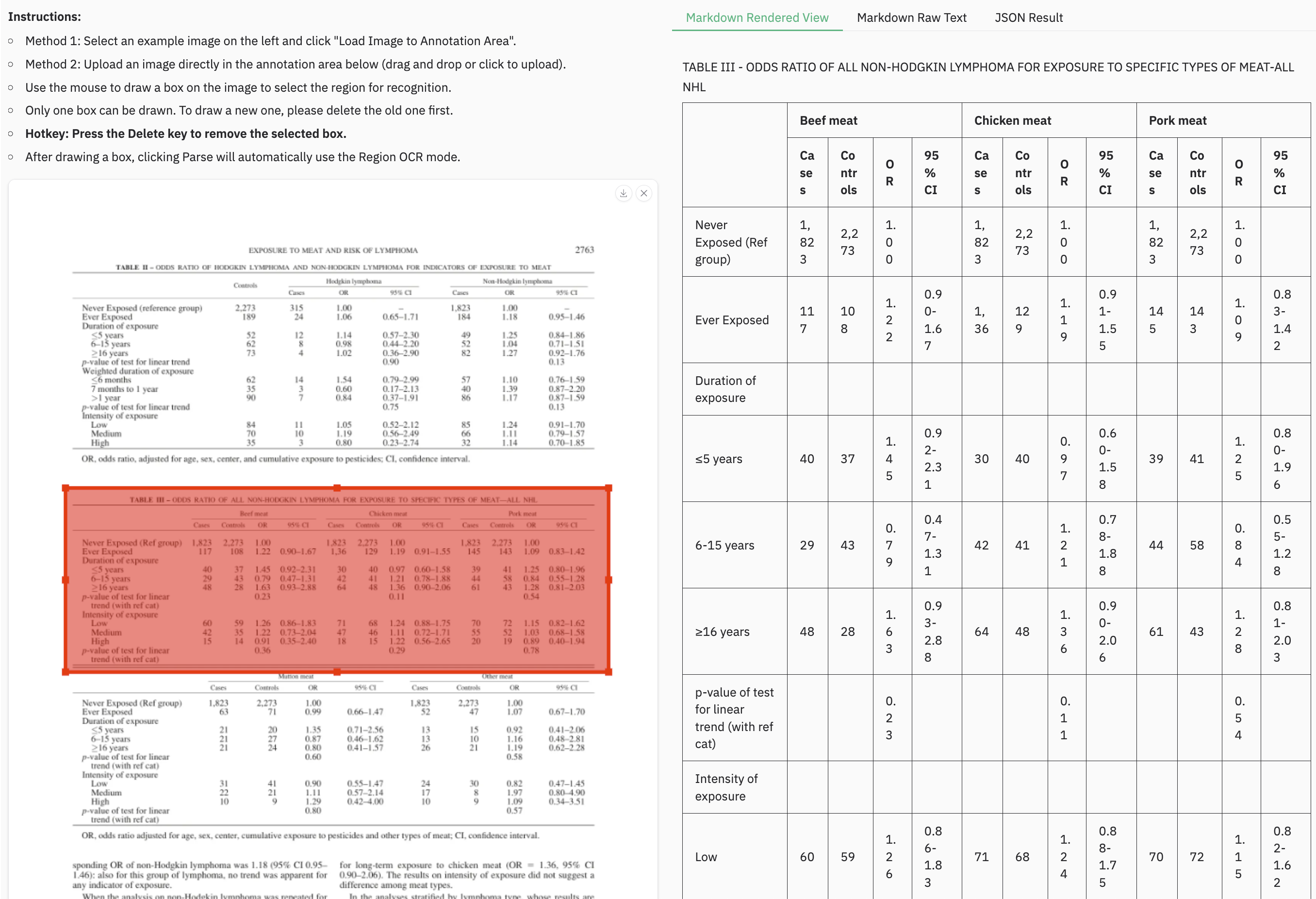 +
+
+## Acknowledgments
+We would like to thank [Qwen2.5-VL](https://github.com/QwenLM/Qwen2.5-VL), [aimv2](https://github.com/apple/ml-aim), [MonkeyOCR](https://github.com/Yuliang-Liu/MonkeyOCR),
+[OmniDocBench](https://github.com/opendatalab/OmniDocBench), [PyMuPDF](https://github.com/pymupdf/PyMuPDF), for providing code and models.
+
+We also thank [DocLayNet](https://github.com/DS4SD/DocLayNet), [M6Doc](https://github.com/HCIILAB/M6Doc), [CDLA](https://github.com/buptlihang/CDLA), [D4LA](https://github.com/AlibabaResearch/AdvancedLiterateMachinery) for providing valuable datasets.
+
+## Limitation & Future Work
+
+- **Complex Document Elements:**
+ - **Table&Formula**: dots.ocr is not yet perfect for high-complexity tables and formula extraction.
+ - **Picture**: Pictures in documents are currently not parsed.
+
+- **Parsing Failures:** The model may fail to parse under certain conditions:
+ - When the character-to-pixel ratio is excessively high. Try enlarging the image or increasing the PDF parsing DPI (a setting of 200 is recommended). However, please note that the model performs optimally on images with a resolution under 11289600 pixels.
+ - Continuous special characters, such as ellipses (`...`) and underscores (`_`), may cause the prediction output to repeat endlessly. In such scenarios, consider using alternative prompts like `prompt_layout_only_en`, `prompt_ocr`, or `prompt_grounding_ocr` ([details here](https://github.com/rednote-hilab/dots.ocr/blob/master/dots_ocr/utils/prompts.py)).
+
+- **Performance Bottleneck:** Despite its 1.7B parameter LLM foundation, **dots.ocr** is not yet optimized for high-throughput processing of large PDF volumes.
+
+We are committed to achieving more accurate table and formula parsing, as well as enhancing the model's OCR capabilities for broader generalization, all while aiming for **a more powerful, more efficient model**. Furthermore, we are actively considering the development of **a more general-purpose perception model** based on Vision-Language Models (VLMs), which would integrate general detection, image captioning, and OCR tasks into a unified framework. **Parsing the content of the pictures in the documents** is also a key priority for our future work.
+We believe that collaboration is the key to tackling these exciting challenges. If you are passionate about advancing the frontiers of document intelligence and are interested in contributing to these future endeavors, we would love to hear from you. Please reach out to us via email at: [yanqing4@xiaohongshu.com].
diff --git a/chat_template.json b/chat_template.json
new file mode 100644
index 0000000..87a662f
--- /dev/null
+++ b/chat_template.json
@@ -0,0 +1,3 @@
+{
+ "chat_template": "{% set image_count = namespace(value=0) %}{% set video_count = namespace(value=0) %}{%- for m in messages %}{%- if m.role == 'system' %}{{- '<|system|>' + m.content + '<|endofsystem|>\n' }}{%- elif m.role == 'user' %}{% if m.content is string %}{{- '<|user|>' + m.content + '<|endofuser|>' }}{% else %} {% for content in m.content %}{% if content['type'] == 'image' or 'image' in content or 'image_url' in content %}{% set image_count.value = image_count.value + 1 %}{% if add_vision_id %}Picture {{ image_count.value }}: {% endif %}<|img|><|imgpad|><|endofimg|>{% elif content['type'] == 'video' or 'video' in content %}{% set video_count.value = video_count.value + 1 %}{% if add_vision_id %}Video {{ video_count.value }}: {% endif %}<|img|><|video_pad|><|endofimg|>{% elif 'text' in content %}{{ content['text'] }}{% endif %}{% endfor %}{%- endif %}{%- elif m.role == 'assistant' %}{{- '<|assistant|>' + m.content }}{%- if not loop.last %}{{- '<|endofassistant|>' }}{%- endif %}{%- endif %}{%- endfor %}{%- if messages[-1].role != 'assistant' %}{{- '<|assistant|>' }}{%- endif %}"
+}
\ No newline at end of file
diff --git a/config.json b/config.json
new file mode 100644
index 0000000..7ea2c09
--- /dev/null
+++ b/config.json
@@ -0,0 +1,51 @@
+{
+ "architectures": [
+ "DotsOCRForCausalLM"
+ ],
+ "model_type": "dots_ocr",
+ "auto_map": {
+ "AutoConfig": "configuration_dots.DotsOCRConfig",
+ "AutoModelForCausalLM": "modeling_dots_ocr.DotsOCRForCausalLM"
+ },
+ "attention_bias": true,
+ "attention_dropout": 0.0,
+ "hidden_act": "silu",
+ "hidden_size": 1536,
+ "initializer_range": 0.02,
+ "intermediate_size": 8960,
+ "max_position_embeddings": 131072,
+ "max_window_layers": 28,
+ "num_attention_heads": 12,
+ "num_hidden_layers": 28,
+ "num_key_value_heads": 2,
+ "rms_norm_eps": 1e-06,
+ "rope_scaling": null,
+ "rope_theta": 1000000,
+ "sliding_window": 131072,
+ "tie_word_embeddings": false,
+ "torch_dtype": "bfloat16",
+ "transformers_version": "4.51.0",
+ "use_cache": true,
+ "use_sliding_window": false,
+ "vocab_size": 151936,
+ "image_token_id": 151665,
+ "video_token_id": 151656,
+ "vision_config": {
+ "embed_dim": 1536,
+ "hidden_size": 1536,
+ "intermediate_size": 4224,
+ "num_hidden_layers": 42,
+ "num_attention_heads": 12,
+ "num_channels": 3,
+ "patch_size": 14,
+ "post_norm": true,
+ "rms_norm_eps": 1e-05,
+ "spatial_merge_size": 2,
+ "temporal_patch_size": 1,
+ "use_bias": false,
+ "attn_implementation": "flash_attention_2",
+ "init_merger_std": 0.02,
+ "initializer_range": 0.02,
+ "is_causal": false
+ }
+}
\ No newline at end of file
diff --git a/configuration.json b/configuration.json
new file mode 100644
index 0000000..4aef15d
--- /dev/null
+++ b/configuration.json
@@ -0,0 +1 @@
+{"framework": "pytorch", "task": "image-text-to-text", "allow_remote": true}
\ No newline at end of file
diff --git a/configuration_dots.py b/configuration_dots.py
new file mode 100644
index 0000000..55901c2
--- /dev/null
+++ b/configuration_dots.py
@@ -0,0 +1,76 @@
+from typing import Any, Optional
+from transformers.configuration_utils import PretrainedConfig
+from transformers.models.qwen2 import Qwen2Config
+from transformers import Qwen2_5_VLProcessor, AutoProcessor
+from transformers.models.auto.configuration_auto import CONFIG_MAPPING
+
+
+class DotsVisionConfig(PretrainedConfig):
+ model_type: str = "dots_vit"
+
+ def __init__(
+ self,
+ embed_dim: int = 1536, # vision encoder embed size
+ hidden_size: int = 1536, # after merger hidden size
+ intermediate_size: int = 4224,
+ num_hidden_layers: int = 42,
+ num_attention_heads: int = 12,
+ num_channels: int = 3,
+ patch_size: int = 14,
+ spatial_merge_size: int = 2,
+ temporal_patch_size: int = 1,
+ rms_norm_eps: float = 1e-5,
+ use_bias: bool = False,
+ attn_implementation="flash_attention_2", # "eager","sdpa","flash_attention_2"
+ initializer_range=0.02,
+ init_merger_std=0.02,
+ is_causal=False, # ve causal forward
+ post_norm=True,
+ gradient_checkpointing=False,
+ **kwargs: Any,
+ ):
+ super().__init__(**kwargs)
+ self.embed_dim = embed_dim
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.num_channels = num_channels
+ self.patch_size = patch_size
+ self.spatial_merge_size = spatial_merge_size
+ self.temporal_patch_size = temporal_patch_size
+ self.rms_norm_eps = rms_norm_eps
+ self.use_bias = use_bias
+ self.attn_implementation = attn_implementation
+ self.initializer_range = initializer_range
+ self.init_merger_std = init_merger_std
+ self.is_causal = is_causal
+ self.post_norm = post_norm
+ self.gradient_checkpointing = gradient_checkpointing
+
+
+
+class DotsOCRConfig(Qwen2Config):
+ model_type = "dots_ocr"
+ def __init__(self,
+ image_token_id = 151665,
+ video_token_id = 151656,
+ vision_config: Optional[dict] = None, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.image_token_id = image_token_id
+ self.video_token_id = video_token_id
+ self.vision_config = DotsVisionConfig(**(vision_config or {}))
+
+ def save_pretrained(self, save_directory, **kwargs):
+ self._auto_class = None
+ super().save_pretrained(save_directory, **kwargs)
+
+
+class DotsVLProcessor(Qwen2_5_VLProcessor):
+ def __init__(self, image_processor=None, tokenizer=None, chat_template=None, **kwargs):
+ super().__init__(image_processor, tokenizer, chat_template=chat_template)
+ self.image_token = "<|imgpad|>" if not hasattr(tokenizer, "image_token") else tokenizer.image_token
+
+
+AutoProcessor.register("dots_ocr", DotsVLProcessor)
+CONFIG_MAPPING.register("dots_ocr", DotsOCRConfig)
diff --git a/generation_config.json b/generation_config.json
new file mode 100644
index 0000000..c6f6906
--- /dev/null
+++ b/generation_config.json
@@ -0,0 +1,7 @@
+{
+ "max_length": 32768,
+ "eos_token_id": [
+ 151643,
+ 151673
+ ]
+}
diff --git a/merges.txt b/merges.txt
new file mode 100644
index 0000000..7ce1d95
--- /dev/null
+++ b/merges.txt
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:599bab54075088774b1733fde865d5bd747cbcc7a547c5bc12610e874e26f5e3
+size 1671839
diff --git a/model-00001-of-00002.safetensors b/model-00001-of-00002.safetensors
new file mode 100644
index 0000000..6a5014f
--- /dev/null
+++ b/model-00001-of-00002.safetensors
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:686da8b6a33f88d4fc83092a1f601dbb12ca4e639942190771a61f5cc287aa24
+size 135
diff --git a/model-00002-of-00002.safetensors b/model-00002-of-00002.safetensors
new file mode 100644
index 0000000..09e3c4a
--- /dev/null
+++ b/model-00002-of-00002.safetensors
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8d00568ee09e48f30b2ebd2b2245f6fa07bb2e1afcc3c0300f8298d6a52abf49
+size 135
diff --git a/model.safetensors.index.json b/model.safetensors.index.json
new file mode 100644
index 0000000..8a62c07
--- /dev/null
+++ b/model.safetensors.index.json
@@ -0,0 +1,650 @@
+{
+ "metadata": {
+ "total_size": 6078358528
+ },
+ "weight_map": {
+ "lm_head.weight": "model-00001-of-00002.safetensors",
+ "model.embed_tokens.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.0.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.0.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.0.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.1.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.1.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.1.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.10.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.10.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.10.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.11.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.11.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.11.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.12.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.12.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.12.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.13.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.13.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.13.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.14.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.14.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.14.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.15.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.15.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.15.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.16.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.16.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.16.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.17.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.17.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.17.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.18.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.18.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.18.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.19.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.19.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.19.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.2.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.2.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.2.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.20.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.20.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.20.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.21.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.21.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.21.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.22.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.22.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.22.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.23.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.23.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.23.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.24.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.24.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.24.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.25.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.25.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.25.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.26.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.26.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.26.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.27.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.27.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.27.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.3.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.3.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.3.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.4.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.4.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.4.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.5.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.5.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.5.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.6.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.6.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.6.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.7.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.7.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.7.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.8.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.8.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.8.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.9.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.9.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.9.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.norm.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.0.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.0.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.0.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.0.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.0.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.0.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.0.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.1.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.1.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.1.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.1.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.1.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.1.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.1.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.10.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.10.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.10.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.10.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.10.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.10.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.10.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.11.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.11.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.11.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.11.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.11.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.11.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.11.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.12.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.12.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.12.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.12.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.12.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.12.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.12.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.13.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.13.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.13.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.13.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.13.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.13.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.13.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.14.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.14.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.14.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.14.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.14.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.14.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.14.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.15.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.15.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.15.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.15.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.15.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.15.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.15.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.16.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.16.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.16.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.16.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.16.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.16.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.16.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.17.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.17.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.17.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.17.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.17.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.17.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.17.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.18.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.18.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.18.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.18.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.18.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.18.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.18.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.19.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.19.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.19.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.19.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.19.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.19.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.19.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.2.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.2.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.2.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.2.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.2.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.2.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.2.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.20.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.20.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.20.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.20.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.20.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.20.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.20.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.21.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.21.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.21.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.21.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.21.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.21.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.21.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.22.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.22.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.22.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.22.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.22.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.22.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.22.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.23.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.23.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.23.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.23.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.23.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.23.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.23.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.24.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.24.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.24.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.24.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.24.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.24.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.24.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.25.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.25.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.25.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.25.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.25.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.25.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.25.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.26.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.26.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.26.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.26.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.26.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.26.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.26.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.27.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.27.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.27.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.27.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.27.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.27.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.27.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.28.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.28.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.28.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.28.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.28.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.28.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.28.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.29.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.29.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.29.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.29.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.29.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.29.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.29.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.3.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.3.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.3.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.3.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.3.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.3.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.3.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.30.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.30.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.30.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.30.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.30.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.30.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.30.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.31.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.31.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.31.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.31.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.31.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.31.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.31.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.32.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.32.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.32.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.32.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.32.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.32.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.32.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.33.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.33.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.33.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.33.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.33.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.33.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.33.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.34.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.34.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.34.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.34.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.34.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.34.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.34.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.35.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.35.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.35.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.35.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.35.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.35.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.35.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.36.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.36.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.36.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.36.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.36.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.36.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.36.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.37.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.37.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.37.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.37.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.37.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.37.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.37.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.38.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.38.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.38.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.38.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.38.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.38.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.38.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.39.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.39.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.39.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.39.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.39.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.39.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.39.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.4.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.4.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.4.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.4.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.4.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.4.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.4.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.40.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.40.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.40.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.40.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.40.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.40.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.40.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.41.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.41.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.41.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.41.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.41.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.41.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.41.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.5.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.5.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.5.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.5.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.5.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.5.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.5.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.6.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.6.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.6.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.6.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.6.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.6.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.6.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.7.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.7.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.7.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.7.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.7.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.7.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.7.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.8.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.8.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.8.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.8.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.8.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.8.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.8.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.9.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.9.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.9.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.9.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.9.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.9.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.9.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.merger.ln_q.bias": "model-00002-of-00002.safetensors",
+ "vision_tower.merger.ln_q.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.merger.mlp.0.bias": "model-00002-of-00002.safetensors",
+ "vision_tower.merger.mlp.0.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.merger.mlp.2.bias": "model-00002-of-00002.safetensors",
+ "vision_tower.merger.mlp.2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.patch_embed.patchifier.norm.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.patch_embed.patchifier.proj.bias": "model-00002-of-00002.safetensors",
+ "vision_tower.patch_embed.patchifier.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.post_trunk_norm.weight": "model-00002-of-00002.safetensors"
+ }
+}
\ No newline at end of file
diff --git a/modeling_dots_ocr.py b/modeling_dots_ocr.py
new file mode 100644
index 0000000..79d1c25
--- /dev/null
+++ b/modeling_dots_ocr.py
@@ -0,0 +1,131 @@
+from typing import List, Optional, Tuple, Union
+
+import torch
+from transformers.modeling_outputs import CausalLMOutputWithPast
+from transformers.models.qwen2 import Qwen2ForCausalLM
+
+from .configuration_dots import DotsVisionConfig, DotsOCRConfig
+from .modeling_dots_vision import DotsVisionTransformer
+
+
+DOTS_VLM_MAX_IMAGES = 200
+
+
+class DotsOCRForCausalLM(Qwen2ForCausalLM):
+ config_class = DotsOCRConfig
+
+ def __init__(self, config: DotsOCRConfig):
+ super().__init__(config)
+
+ if isinstance(self.config.vision_config, dict):
+ vision_config = DotsVisionConfig(**self.config.vision_config)
+ self.config.vision_config = vision_config
+ else:
+ vision_config = self.config.vision_config
+
+ self.vision_tower = DotsVisionTransformer(vision_config)
+
+ def prepare_inputs_embeds(
+ self,
+ input_ids: torch.LongTensor,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ grid_thw: Optional[torch.FloatTensor] = None,
+ img_mask: Optional[torch.BoolTensor] = None,
+ ) -> torch.Tensor:
+ inputs_embeds = self.get_input_embeddings()(input_ids)
+
+ if pixel_values is not None:
+ assert img_mask is not None
+ if grid_thw.shape[0] > DOTS_VLM_MAX_IMAGES:
+ print(
+ f"Num image exceeded: {grid_thw.shape[0]} > {DOTS_VLM_MAX_IMAGES}, which may cause FSDP hang"
+ )
+
+ vision_embeddings = self.vision_tower(pixel_values, grid_thw)
+
+ true_indices = torch.nonzero(img_mask).squeeze()
+ if len(true_indices) > vision_embeddings.size(0):
+ print(
+ f"img_mask sum > VE and will be truncated, mask.sum()={len(true_indices)} {vision_embeddings.size(0)=}"
+ )
+ true_indices = true_indices[: vision_embeddings.size(0)]
+ new_img_mask = torch.zeros_like(img_mask, device=img_mask.device)
+ new_img_mask[true_indices[:, 0], true_indices[:, 1]] = True
+ else:
+ new_img_mask = img_mask
+
+ assert (
+ vision_embeddings.size(0) == new_img_mask.sum()
+ ), f"{vision_embeddings.size(0)=}, {new_img_mask.sum()=}"
+
+ inputs_embeds = inputs_embeds.masked_scatter(
+ new_img_mask.to(inputs_embeds.device).unsqueeze(-1).expand_as(inputs_embeds),
+ vision_embeddings.to(inputs_embeds.device).type(inputs_embeds.dtype),
+ )
+
+ return inputs_embeds
+
+ def forward(
+ self,
+ input_ids: torch.LongTensor,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ image_grid_thw: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ use_cache: Optional[bool] = None,
+ logits_to_keep: int = 0,
+ **loss_kwargs,
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ assert len(input_ids) >= 1, f"empty input_ids {input_ids.shape=} will cause gradnorm nan"
+ if inputs_embeds is None:
+ img_mask = input_ids == self.config.image_token_id
+ inputs_embeds = self.prepare_inputs_embeds(input_ids, pixel_values, image_grid_thw, img_mask)
+
+ outputs = super().forward(
+ inputs_embeds=inputs_embeds,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ labels=labels,
+ use_cache=use_cache if use_cache is not None else self.config.use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ # return_dict=return_dict,
+ logits_to_keep=logits_to_keep,
+ **loss_kwargs,
+ )
+
+ return outputs
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ inputs_embeds=None,
+ pixel_values=None,
+ attention_mask=None,
+ cache_position=None,
+ num_logits_to_keep=None,
+ **kwargs,
+ ):
+ model_inputs = super().prepare_inputs_for_generation(
+ input_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ attention_mask=attention_mask,
+ cache_position=cache_position,
+ num_logits_to_keep=num_logits_to_keep,
+ **kwargs,
+ )
+
+ if cache_position[0] == 0:
+ model_inputs["pixel_values"] = pixel_values
+
+ return model_inputs
diff --git a/modeling_dots_ocr_vllm.py b/modeling_dots_ocr_vllm.py
new file mode 100644
index 0000000..07195e8
--- /dev/null
+++ b/modeling_dots_ocr_vllm.py
@@ -0,0 +1,429 @@
+from functools import cached_property
+from typing import Iterable, Literal, Mapping, Optional, Set, Tuple, TypedDict, Union
+
+import torch
+import torch.nn as nn
+from transformers.models.qwen2_vl import Qwen2VLImageProcessor, Qwen2VLProcessor
+from transformers.models.qwen2_vl.image_processing_qwen2_vl import smart_resize
+from vllm import ModelRegistry
+from vllm.config import VllmConfig
+from vllm.model_executor.layers.sampler import SamplerOutput, get_sampler
+from vllm.model_executor.models.interfaces import MultiModalEmbeddings, SupportsMultiModal
+from vllm.model_executor.models.qwen2 import Qwen2ForCausalLM
+from vllm.model_executor.models.qwen2_5_vl import (
+ Qwen2_5_VLMultiModalProcessor,
+ Qwen2_5_VLProcessingInfo,
+)
+from vllm.model_executor.models.qwen2_vl import Qwen2VLDummyInputsBuilder
+from vllm.model_executor.models.utils import (
+ AutoWeightsLoader,
+ WeightsMapper,
+ init_vllm_registered_model,
+ maybe_prefix,
+ merge_multimodal_embeddings,
+)
+from vllm.model_executor.sampling_metadata import SamplingMetadata
+from vllm.multimodal import MULTIMODAL_REGISTRY
+from vllm.multimodal.inputs import MultiModalDataDict
+from vllm.multimodal.parse import ImageSize
+from vllm.sequence import IntermediateTensors
+
+from .configuration_dots import DotsVisionConfig
+from .configuration_dots import DotsOCRConfig
+from .modeling_dots_vision import DotsVisionTransformer
+
+
+class DotsOCRImagePixelInputs(TypedDict):
+ type: Literal["pixel_values", "image_grid_thw"]
+
+ pixel_values: torch.Tensor
+ image_grid_thw: torch.Tensor
+
+
+class DotsOCRImageEmbeddingInputs(TypedDict):
+ type: Literal["image_embeds", "image_grid_thw"]
+ image_embeds: torch.Tensor
+ """Supported types:
+ - List[`torch.Tensor`]: A list of tensors holding all images' features.
+ Each tensor holds an image's features.
+ - `torch.Tensor`: A tensor holding all images' features
+ (concatenation of all images' feature tensors).
+
+ Tensor shape: `(num_image_features, hidden_size)`
+ - `num_image_features` varies based on
+ the number and resolution of the images.
+ - `hidden_size` must match the hidden size of language model backbone.
+ """
+
+ image_grid_thw: torch.Tensor
+
+
+DotsOCRImageInputs = Union[DotsOCRImagePixelInputs, DotsOCRImageEmbeddingInputs]
+
+
+class DotsOCRMultiModalProcessor(Qwen2_5_VLMultiModalProcessor):
+ pass
+
+
+class DotsOCRDummyInputsBuilder(Qwen2VLDummyInputsBuilder):
+ def get_dummy_mm_data(
+ self,
+ seq_len: int,
+ mm_counts: Mapping[str, int],
+ ) -> MultiModalDataDict:
+ num_images = mm_counts.get("image", 0)
+
+ target_width, target_height = self.info.get_image_size_with_most_features()
+
+ return {
+ "image": self._get_dummy_images(width=target_width, height=target_height, num_images=num_images),
+ }
+
+
+class DotsOCRProcessingInfo(Qwen2_5_VLProcessingInfo):
+ def get_hf_config(self) -> DotsOCRConfig:
+ config = self.ctx.get_hf_config()
+ if not config.__class__.__name__ == 'DotsOCRConfig':
+ raise TypeError(f"Expected DotsOCRConfig, got {type(config)}")
+
+ if hasattr(config, "vision_config") and isinstance(config.vision_config, dict):
+ config.vision_config = DotsVisionConfig(**config.vision_config)
+
+ return config
+
+ def get_hf_processor(
+ self,
+ *,
+ min_pixels: Optional[int] = None,
+ max_pixels: Optional[int] = None,
+ size: Optional[dict[str, int]] = None,
+ **kwargs: object,
+ ) -> Qwen2VLProcessor:
+ processor = self.ctx.get_hf_processor(
+ Qwen2VLProcessor,
+ image_processor=self.get_image_processor(min_pixels=min_pixels, max_pixels=max_pixels, size=size),
+ **kwargs,
+ )
+ processor.image_token = "<|imgpad|>"
+ processor.video_token = "<|video_pad|>"
+ return processor
+
+ def _get_vision_info(
+ self,
+ *,
+ image_width: int,
+ image_height: int,
+ num_frames: int = 1,
+ do_resize: bool = True,
+ image_processor: Optional[Qwen2VLImageProcessor],
+ ) -> tuple[ImageSize, int]:
+ if image_processor is None:
+ image_processor = self.get_image_processor()
+
+ hf_config: DotsOCRConfig = self.get_hf_config()
+ vision_config = hf_config.vision_config
+ patch_size = vision_config.patch_size
+ merge_size = vision_config.spatial_merge_size
+ temporal_patch_size = vision_config.temporal_patch_size
+
+ if do_resize:
+ resized_height, resized_width = smart_resize(
+ height=image_height,
+ width=image_width,
+ factor=patch_size * merge_size,
+ min_pixels=image_processor.min_pixels,
+ max_pixels=image_processor.max_pixels,
+ )
+ preprocessed_size = ImageSize(width=resized_width, height=resized_height)
+ else:
+ preprocessed_size = ImageSize(width=image_width, height=image_height)
+
+ # NOTE: Frames are padded to be divisible by `temporal_patch_size`
+ # https://github.com/huggingface/transformers/blob/v4.48.3/src/transformers/models/qwen2_vl/image_processing_qwen2_vl.py#L294
+ padded_num_frames = num_frames + num_frames % temporal_patch_size
+
+ grid_t = max(padded_num_frames // temporal_patch_size, 1)
+ grid_h = preprocessed_size.height // patch_size
+ grid_w = preprocessed_size.width // patch_size
+
+ num_patches = grid_t * grid_h * grid_w
+ num_vision_tokens = num_patches // (merge_size**2)
+
+ return preprocessed_size, num_vision_tokens
+
+
+@MULTIMODAL_REGISTRY.register_processor(
+ Qwen2_5_VLMultiModalProcessor,
+ info=DotsOCRProcessingInfo,
+ dummy_inputs=DotsOCRDummyInputsBuilder,
+)
+class DotsOCRForCausalLM(nn.Module, SupportsMultiModal):
+ hf_to_vllm_mapper = WeightsMapper(
+ orig_to_new_prefix={
+ "lm_head.": "language_model.lm_head.",
+ "model.": "language_model.model.",
+ }
+ )
+ _tp_plan = {}
+
+ def __init__(self, *, vllm_config: VllmConfig, prefix: str = ""):
+ super().__init__()
+
+ self.config: DotsOCRConfig = vllm_config.model_config.hf_config
+ self.quant_config = vllm_config.quant_config
+ self.multimodal_config = vllm_config.model_config.multimodal_config
+
+ if isinstance(self.config.vision_config, dict):
+ vision_config = DotsVisionConfig(**self.config.vision_config)
+ self.config.vision_config = vision_config
+ else:
+ vision_config = self.config.vision_config
+
+ self.vision_tower = DotsVisionTransformer(vision_config)
+ self.language_model: Qwen2ForCausalLM = init_vllm_registered_model(
+ vllm_config=vllm_config,
+ hf_config=self.config,
+ prefix=maybe_prefix(prefix, "language_model"),
+ architectures=["Qwen2ForCausalLM"],
+ )
+
+ @cached_property
+ def sampler(self):
+ if hasattr(self.language_model, "sampler"):
+ return self.language_model.sampler
+
+ return get_sampler()
+
+ def _validate_and_reshape_mm_tensor(self, mm_input: object, name: str) -> torch.Tensor:
+ if not isinstance(mm_input, (torch.Tensor, list)):
+ raise ValueError(f"Incorrect type of {name}. " f"Got type: {type(mm_input)}")
+ if isinstance(mm_input, torch.Tensor):
+ if mm_input.ndim == 2:
+ return mm_input
+ if mm_input.ndim != 3:
+ raise ValueError(
+ f"{name} should be 2D or batched 3D tensor. "
+ f"Got ndim: {mm_input.ndim} "
+ f"(shape={mm_input.shape})"
+ )
+ return torch.concat(list(mm_input))
+ else:
+ return torch.concat(mm_input)
+
+ def _parse_and_validate_image_input(self, **kwargs: object) -> Optional[DotsOCRImageInputs]:
+ pixel_values = kwargs.pop("pixel_values", None)
+ image_embeds = kwargs.pop("image_embeds", None)
+ image_grid_thw = kwargs.pop("image_grid_thw", None)
+
+ if pixel_values is None and image_embeds is None:
+ return None
+
+ if pixel_values is not None:
+ pixel_values = self._validate_and_reshape_mm_tensor(pixel_values, "image pixel values")
+ image_grid_thw = self._validate_and_reshape_mm_tensor(image_grid_thw, "image grid_thw")
+
+ if not isinstance(pixel_values, (torch.Tensor, list)):
+ raise ValueError("Incorrect type of image pixel values. " f"Got type: {type(pixel_values)}")
+
+ return DotsOCRImagePixelInputs(
+ type="pixel_values", pixel_values=pixel_values, image_grid_thw=image_grid_thw
+ )
+
+ if image_embeds is not None:
+ image_embeds = self._validate_and_reshape_mm_tensor(image_embeds, "image embeds")
+ image_grid_thw = self._validate_and_reshape_mm_tensor(image_grid_thw, "image grid_thw")
+
+ if not isinstance(image_embeds, torch.Tensor):
+ raise ValueError("Incorrect type of image embeddings. " f"Got type: {type(image_embeds)}")
+ return DotsOCRImageEmbeddingInputs(
+ type="image_embeds", image_embeds=image_embeds, image_grid_thw=image_grid_thw
+ )
+
+ def vision_forward(self, pixel_values: torch.Tensor, image_grid_thw: torch.Tensor):
+ from vllm.distributed import (
+ get_tensor_model_parallel_group,
+ get_tensor_model_parallel_rank,
+ get_tensor_model_parallel_world_size,
+ )
+
+ assert self.vision_tower is not None
+
+ tp_rank = get_tensor_model_parallel_rank()
+ tp = get_tensor_model_parallel_world_size()
+
+ image_grid_thw_chunk = image_grid_thw.chunk(tp)
+ image_sizes_consum = torch.tensor([i.prod(-1).sum() for i in image_grid_thw_chunk]).cumsum(dim=0)
+ merge_size_square = self.vision_tower.config.spatial_merge_size**2
+ image_embedding = torch.zeros(
+ (
+ pixel_values.shape[0] // merge_size_square,
+ self.vision_tower.config.hidden_size,
+ ),
+ device=pixel_values.device,
+ dtype=pixel_values.dtype,
+ )
+
+ if tp_rank < len(image_sizes_consum):
+ idx_start = 0 if tp_rank == 0 else image_sizes_consum[tp_rank - 1].item()
+ idx_end = image_sizes_consum[tp_rank].item()
+ pixel_values_part = pixel_values[idx_start:idx_end]
+ image_grid_thw_part = image_grid_thw_chunk[tp_rank]
+ image_embedding_part = self.vision_tower(pixel_values_part, image_grid_thw_part)
+ image_embedding[idx_start // merge_size_square : idx_end // merge_size_square] = image_embedding_part
+
+ group = get_tensor_model_parallel_group().device_group
+ torch.distributed.all_reduce(image_embedding, group=group)
+ return image_embedding
+
+ def _process_image_input(self, image_input: DotsOCRImageInputs) -> tuple[torch.Tensor, ...]:
+ grid_thw = image_input["image_grid_thw"]
+ assert grid_thw.ndim == 2
+
+ if image_input["type"] == "image_embeds":
+ image_embeds = image_input["image_embeds"].type(self.vision_tower.dtype)
+ else:
+ pixel_values = image_input["pixel_values"].type(self.vision_tower.dtype)
+ image_embeds = self.vision_forward(pixel_values, grid_thw)[
+ :, : self.config.hidden_size
+ ]
+
+ # Split concatenated embeddings for each image item.
+ merge_size = self.vision_tower.config.spatial_merge_size
+ sizes = grid_thw.prod(-1) // merge_size // merge_size
+
+ return image_embeds.split(sizes.tolist())
+
+ def _parse_and_validate_multimodal_inputs(self, **kwargs: object) -> dict:
+ modalities = {}
+
+ # Preserve the order of modalities if there are multiple of them
+ # from the order of kwargs.
+ for input_key in kwargs:
+ if input_key in ("pixel_values", "image_embeds") and "images" not in modalities:
+ modalities["images"] = self._parse_and_validate_image_input(**kwargs)
+ return modalities
+
+ def get_language_model(self) -> torch.nn.Module:
+ return self.language_model
+
+ def get_multimodal_embeddings(self, **kwargs: object) -> Optional[MultiModalEmbeddings]:
+ modalities = self._parse_and_validate_multimodal_inputs(**kwargs)
+ if not modalities:
+ return None
+
+ # The result multimodal_embeddings is tuple of tensors, with each
+ # tensor correspoending to a multimodal data item (image or video).
+ multimodal_embeddings: tuple[torch.Tensor, ...] = ()
+
+ # NOTE: It is important to iterate over the keys in this dictionary
+ # to preserve the order of the modalities.
+ for modality in modalities:
+ if modality == "images":
+ image_input = modalities["images"]
+ vision_embeddings = self._process_image_input(image_input)
+ multimodal_embeddings += vision_embeddings
+
+ return multimodal_embeddings
+
+ def get_input_embeddings(
+ self,
+ input_ids: torch.Tensor,
+ multimodal_embeddings: Optional[MultiModalEmbeddings] = None,
+ ) -> torch.Tensor:
+ inputs_embeds = self.language_model.get_input_embeddings(input_ids)
+ if multimodal_embeddings is not None:
+ inputs_embeds = merge_multimodal_embeddings(
+ input_ids,
+ inputs_embeds,
+ multimodal_embeddings,
+ [self.config.image_token_id, self.config.video_token_id],
+ )
+
+ return inputs_embeds
+
+ def get_input_embeddings_v0(
+ self,
+ input_ids: torch.Tensor,
+ image_input: Optional[DotsOCRImagePixelInputs] = None,
+ ) -> torch.Tensor:
+ inputs_embeds = self.get_input_embeddings(input_ids)
+ if image_input is not None:
+ image_embeds = self._process_image_input(image_input)
+ inputs_embeds = merge_multimodal_embeddings(
+ input_ids,
+ inputs_embeds,
+ image_embeds,
+ placeholder_token_id=self.config.image_token_id,
+ )
+ return inputs_embeds
+
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor],
+ positions: torch.Tensor,
+ intermediate_tensors: Optional[IntermediateTensors] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ **kwargs,
+ ) -> Union[torch.Tensor, IntermediateTensors]:
+ if intermediate_tensors is not None:
+ inputs_embeds = None
+ elif inputs_embeds is None and kwargs.get("pixel_values") is not None:
+ image_input = self._parse_and_validate_image_input(**kwargs)
+ if image_input is None:
+ inputs_embeds = None
+ else:
+ assert input_ids is not None
+ inputs_embeds = self.get_input_embeddings_v0(
+ input_ids,
+ image_input=image_input,
+ )
+ input_ids = None
+
+ hidden_states = self.language_model(
+ input_ids=input_ids,
+ positions=positions,
+ intermediate_tensors=intermediate_tensors,
+ inputs_embeds=inputs_embeds,
+ )
+
+ return hidden_states
+
+ def compute_logits(
+ self,
+ hidden_states: torch.Tensor,
+ sampling_metadata: SamplingMetadata,
+ ) -> Optional[torch.Tensor]:
+ return self.language_model.compute_logits(hidden_states, sampling_metadata)
+
+ def sample(
+ self,
+ logits: Optional[torch.Tensor],
+ sampling_metadata: SamplingMetadata,
+ ) -> Optional[SamplerOutput]:
+ next_tokens = self.sampler(logits, sampling_metadata)
+ return next_tokens
+
+ def load_weights(self, weights: Iterable[Tuple[str, torch.Tensor]]) -> Set[str]:
+ loader = AutoWeightsLoader(self)
+ return loader.load_weights(weights, mapper=self.hf_to_vllm_mapper)
+
+
+def patch_vllm_chat_placeholder():
+ from vllm.entrypoints.chat_utils import BaseMultiModalItemTracker
+
+ ori = BaseMultiModalItemTracker._placeholder_str
+
+ def _placeholder_str(self, modality, current_count: int) -> Optional[str]:
+ hf_config = self._model_config.hf_config
+ model_type = hf_config.model_type
+ if modality in ("image",) and model_type in ["dots_ocr"]:
+ return "<|img|><|imgpad|><|endofimg|>"
+ return ori(self, modality, current_count)
+
+ BaseMultiModalItemTracker._placeholder_str = _placeholder_str
+
+ModelRegistry.register_model(
+ "DotsOCRForCausalLM", DotsOCRForCausalLM,
+)
+
+patch_vllm_chat_placeholder()
\ No newline at end of file
diff --git a/modeling_dots_vision.py b/modeling_dots_vision.py
new file mode 100644
index 0000000..62a1bdf
--- /dev/null
+++ b/modeling_dots_vision.py
@@ -0,0 +1,405 @@
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from flash_attn import flash_attn_varlen_func
+from torch.nn import LayerNorm
+from transformers.modeling_utils import PreTrainedModel
+from .configuration_dots import DotsVisionConfig
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb_vision(tensor: torch.Tensor, freqs: torch.Tensor) -> torch.Tensor:
+ orig_dtype = tensor.dtype
+ tensor = tensor.float()
+
+ cos = freqs.cos()
+ sin = freqs.sin()
+
+ cos = cos.unsqueeze(1).repeat(1, 1, 2).unsqueeze(0).float()
+ sin = sin.unsqueeze(1).repeat(1, 1, 2).unsqueeze(0).float()
+
+ output = (tensor * cos) + (rotate_half(tensor) * sin)
+
+ output = output.to(orig_dtype)
+
+ return output
+
+
+class VisionRotaryEmbedding(nn.Module):
+ def __init__(self, dim: int, theta: float = 10000.0) -> None:
+ super().__init__()
+ inv_freq = 1.0 / (theta ** (torch.arange(0, dim, 2, dtype=torch.float) / dim))
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+
+ def forward(self, seqlen: int) -> torch.Tensor:
+ seq = torch.arange(seqlen, device=self.inv_freq.device, dtype=self.inv_freq.dtype)
+ freqs = torch.outer(seq, self.inv_freq)
+ return freqs
+
+
+class PatchMerger(nn.Module):
+ def __init__(
+ self,
+ dim: int,
+ context_dim: int,
+ spatial_merge_size: int = 2,
+ pre_norm="layernorm",
+ init_merger_std=None,
+ ) -> None:
+ super().__init__()
+ self.hidden_size = context_dim * (spatial_merge_size**2)
+ self.pre_norm = pre_norm
+ if self.pre_norm == "layernorm":
+ self.ln_q = LayerNorm(context_dim, eps=1e-6)
+ elif self.pre_norm == "rmsnorm":
+ self.ln_q = RMSNorm(context_dim, eps=1e-6)
+ else:
+ print("no norm in patch merger")
+
+ self.mlp = nn.Sequential(
+ nn.Linear(self.hidden_size, self.hidden_size),
+ nn.GELU(),
+ nn.Linear(self.hidden_size, dim),
+ )
+
+ if init_merger_std is not None:
+ nn.init.normal_(self.mlp[0].weight, mean=0.0, std=init_merger_std)
+ nn.init.zeros_(self.mlp[0].bias)
+ nn.init.normal_(self.mlp[2].weight, mean=0.0, std=init_merger_std)
+ nn.init.zeros_(self.mlp[2].bias)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ if self.pre_norm:
+ x = self.mlp(self.ln_q(x).view(-1, self.hidden_size))
+ else:
+ x = self.mlp(x.view(-1, self.hidden_size))
+ return x
+
+
+class VisionAttention(nn.Module):
+ def __init__(self, config, dim: int, num_heads: int = 16, bias=True) -> None:
+ super().__init__()
+ self.num_heads = num_heads
+ self.head_dim = dim // num_heads
+ self.qkv = nn.Linear(dim, dim * 3, bias=bias)
+ self.proj = nn.Linear(dim, dim, bias=bias)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ cu_seqlens: torch.Tensor,
+ rotary_pos_emb: torch.Tensor = None,
+ ) -> torch.Tensor:
+ seq_length = hidden_states.shape[0]
+
+ q, k, v = self.qkv(hidden_states).reshape(seq_length, 3, self.num_heads, -1).permute(1, 0, 2, 3).unbind(0)
+ q = apply_rotary_pos_emb_vision(q.unsqueeze(0), rotary_pos_emb).squeeze(0)
+ k = apply_rotary_pos_emb_vision(k.unsqueeze(0), rotary_pos_emb).squeeze(0)
+
+ attention_mask = torch.full(
+ [1, seq_length, seq_length], torch.finfo(q.dtype).min, device=q.device, dtype=q.dtype
+ )
+ for i in range(1, len(cu_seqlens)):
+ attention_mask[..., cu_seqlens[i - 1] : cu_seqlens[i], cu_seqlens[i - 1] : cu_seqlens[i]] = 0
+
+ q = q.transpose(0, 1)
+ k = k.transpose(0, 1)
+ v = v.transpose(0, 1)
+ attn_weights = torch.matmul(q, k.transpose(1, 2)) / math.sqrt(self.head_dim)
+ attn_weights = attn_weights + attention_mask
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(q.dtype)
+ attn_output = torch.matmul(attn_weights, v)
+ attn_output = attn_output.transpose(0, 1)
+ attn_output = attn_output.reshape(seq_length, -1)
+ attn_output = self.proj(attn_output)
+ return attn_output
+
+
+class VisionFlashAttention2(nn.Module):
+ def __init__(self, config, dim: int, num_heads: int = 16, bias=True) -> None:
+ super().__init__()
+ self.num_heads = num_heads
+ self.qkv = nn.Linear(dim, dim * 3, bias=bias)
+ self.proj = nn.Linear(dim, dim, bias=bias)
+ self.config = config
+ self.is_causal = config.is_causal
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ cu_seqlens: torch.Tensor,
+ rotary_pos_emb: torch.Tensor = None,
+ ) -> torch.Tensor:
+ seq_length = hidden_states.shape[0]
+ q, k, v = (
+ self.qkv(hidden_states).reshape(seq_length, 3, self.num_heads, -1).permute(1, 0, 2, 3).unbind(0)
+ ) # 'shd'
+ q = apply_rotary_pos_emb_vision(q.unsqueeze(0), rotary_pos_emb).squeeze(0)
+ k = apply_rotary_pos_emb_vision(k.unsqueeze(0), rotary_pos_emb).squeeze(0)
+ max_seqlen = (cu_seqlens[1:] - cu_seqlens[:-1]).max().item()
+ attn_output = flash_attn_varlen_func(
+ q, k, v, cu_seqlens, cu_seqlens, max_seqlen, max_seqlen, causal=self.is_causal
+ ).reshape(seq_length, -1)
+ attn_output = self.proj(attn_output)
+
+ return attn_output
+
+
+class VisionSdpaAttention(nn.Module):
+ def __init__(self, config, dim: int, num_heads: int = 16, bias=True) -> None:
+ super().__init__()
+ self.num_heads = num_heads
+ self.qkv = nn.Linear(dim, dim * 3, bias=bias)
+ self.proj = nn.Linear(dim, dim, bias=bias)
+ self.config = config
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ cu_seqlens: torch.Tensor,
+ rotary_pos_emb: torch.Tensor = None,
+ ) -> torch.Tensor:
+ seq_length = hidden_states.shape[0]
+ q, k, v = self.qkv(hidden_states).reshape(seq_length, 3, self.num_heads, -1).permute(1, 0, 2, 3).unbind(0)
+
+ q = apply_rotary_pos_emb_vision(q.unsqueeze(0), rotary_pos_emb).squeeze(0)
+ k = apply_rotary_pos_emb_vision(k.unsqueeze(0), rotary_pos_emb).squeeze(0)
+
+ attention_mask = torch.zeros([1, seq_length, seq_length], device=q.device, dtype=torch.bool)
+ for i in range(1, len(cu_seqlens)):
+ attention_mask[..., cu_seqlens[i - 1] : cu_seqlens[i], cu_seqlens[i - 1] : cu_seqlens[i]] = True
+
+ q = q.transpose(0, 1)
+ k = k.transpose(0, 1)
+ v = v.transpose(0, 1)
+
+ attn_output = F.scaled_dot_product_attention(q, k, v, attention_mask, dropout_p=0.0)
+ attn_output = attn_output.transpose(0, 1)
+ attn_output = attn_output.reshape(seq_length, -1)
+
+ attn_output = self.proj(attn_output)
+ return attn_output
+
+
+DOTS_VISION_ATTENTION_CLASSES = {
+ "eager": VisionAttention,
+ "flash_attention_2": VisionFlashAttention2,
+ "sdpa": VisionSdpaAttention,
+}
+
+
+class RMSNorm(nn.Module):
+ def __init__(self, dim: int, eps: float = 1e-6):
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(dim))
+ self.eps = eps
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ output = self._norm(x.float()).type_as(x)
+ return output * self.weight
+
+ def extra_repr(self) -> str:
+ return f"{tuple(self.weight.shape)}, eps={self.eps}"
+
+ def _norm(self, x: torch.Tensor) -> torch.Tensor:
+ return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
+
+
+class DotsSwiGLUFFN(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ hidden_features = config.intermediate_size
+ in_features = config.embed_dim
+ bias = config.use_bias
+
+ self.fc1 = nn.Linear(in_features, hidden_features, bias=bias)
+ self.fc2 = nn.Linear(hidden_features, in_features, bias=bias)
+ self.fc3 = nn.Linear(in_features, hidden_features, bias=bias)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ x = F.silu(self.fc1(x)) * self.fc3(x)
+ x = self.fc2(x)
+ return x
+
+
+
+class DotsPatchEmbed(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.num_channels = config.num_channels
+ self.patch_size = config.patch_size
+ self.temporal_patch_size = config.temporal_patch_size
+ self.embed_dim = config.embed_dim
+ self.config = config
+ self.proj = nn.Conv2d(
+ config.num_channels,
+ config.embed_dim,
+ kernel_size=(config.patch_size, config.patch_size),
+ stride=(config.patch_size, config.patch_size),
+ )
+ self.norm = RMSNorm(config.embed_dim, eps=config.rms_norm_eps)
+
+ def forward(self, x: torch.Tensor, grid_thw=None) -> torch.Tensor:
+ x = x.view(-1, self.num_channels, self.temporal_patch_size, self.patch_size, self.patch_size)[:, :, 0]
+ x = self.proj(x).view(-1, self.embed_dim)
+ x = self.norm(x)
+ return x
+
+
+class DotsViTPreprocessor(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.patch_h = config.patch_size
+ self.patch_w = config.patch_size
+ self.embed_dim = config.embed_dim
+ self.config = config
+ self.patchifier = DotsPatchEmbed(config)
+
+ def forward(self, x: torch.Tensor, grid_thw=None) -> torch.Tensor:
+ tokens = self.patchifier(x, grid_thw)
+ return tokens
+
+
+class DotsVisionBlock(nn.Module):
+ def __init__(self, config, attn_implementation: str = "flash_attention_2"):
+ super().__init__()
+ self.attn = DOTS_VISION_ATTENTION_CLASSES[attn_implementation](
+ config, config.embed_dim, num_heads=config.num_attention_heads, bias=config.use_bias
+ )
+ self.norm1 = RMSNorm(config.embed_dim, eps=config.rms_norm_eps)
+ self.mlp = DotsSwiGLUFFN(config)
+ self.norm2 = RMSNorm(config.embed_dim, eps=config.rms_norm_eps)
+
+ def forward(self, hidden_states, cu_seqlens, rotary_pos_emb) -> torch.Tensor:
+ hidden_states = hidden_states + self.attn(
+ self.norm1(hidden_states), cu_seqlens=cu_seqlens, rotary_pos_emb=rotary_pos_emb
+ )
+ hidden_states = hidden_states + self.mlp(self.norm2(hidden_states))
+ return hidden_states
+
+
+class DotsVisionTransformer(PreTrainedModel):
+ def __init__(self, config: DotsVisionConfig) -> None:
+ super().__init__(config)
+ self.config = config
+ self.spatial_merge_size = config.spatial_merge_size
+
+ self.patch_embed = DotsViTPreprocessor(config)
+ self._init_weights(self.patch_embed.patchifier.proj)
+
+ head_dim = config.embed_dim // config.num_attention_heads
+
+ self.rotary_pos_emb = VisionRotaryEmbedding(head_dim // 2)
+
+ _num_hidden_layers = config.num_hidden_layers
+ self.blocks = nn.ModuleList(
+ [DotsVisionBlock(config, config.attn_implementation) for _ in range(_num_hidden_layers)]
+ )
+
+ if self.config.post_norm:
+ self.post_trunk_norm = RMSNorm(config.embed_dim, eps=config.rms_norm_eps)
+
+ self.merger = PatchMerger(
+ dim=config.hidden_size,
+ context_dim=config.embed_dim,
+ spatial_merge_size=config.spatial_merge_size,
+ init_merger_std=self.config.init_merger_std,
+ )
+
+ self.gradient_checkpointing = False
+ self._gradient_checkpointing_func = torch.utils.checkpoint.checkpoint
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, (nn.Linear, nn.Conv3d)):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+ @property
+ def dtype(self) -> torch.dtype:
+ return self.blocks[0].mlp.fc2.weight.dtype
+
+ @property
+ def device(self) -> torch.device:
+ return self.blocks[0].mlp.fc2.weight.device
+
+ def get_pos_ids_by_grid(self, grid_thw):
+ pos_ids = []
+ for t, h, w in grid_thw:
+ hpos_ids = torch.arange(h).unsqueeze(1).expand(-1, w)
+ hpos_ids = hpos_ids.reshape(
+ h // self.spatial_merge_size,
+ self.spatial_merge_size,
+ w // self.spatial_merge_size,
+ self.spatial_merge_size,
+ )
+ hpos_ids = hpos_ids.permute(0, 2, 1, 3)
+ hpos_ids = hpos_ids.flatten()
+
+ wpos_ids = torch.arange(w).unsqueeze(0).expand(h, -1)
+ wpos_ids = wpos_ids.reshape(
+ h // self.spatial_merge_size,
+ self.spatial_merge_size,
+ w // self.spatial_merge_size,
+ self.spatial_merge_size,
+ )
+ wpos_ids = wpos_ids.permute(0, 2, 1, 3)
+ wpos_ids = wpos_ids.flatten()
+ pos_ids.append(
+ torch.stack([hpos_ids, wpos_ids], dim=-1).repeat(t, 1)
+ )
+
+ return pos_ids
+
+ def rot_pos_emb(self, grid_thw):
+ pos_ids = self.get_pos_ids_by_grid(grid_thw)
+ pos_ids = torch.cat(pos_ids, dim=0)
+ max_grid_size = grid_thw[:, 1:].max()
+ rotary_pos_emb_full = self.rotary_pos_emb(max_grid_size)
+ rotary_pos_emb = rotary_pos_emb_full[pos_ids].flatten(1)
+ return rotary_pos_emb
+
+ def forward(self, hidden_states: torch.Tensor, grid_thw: torch.Tensor, bf16=True) -> torch.Tensor:
+ if bf16:
+ hidden_states = hidden_states.bfloat16()
+ hidden_states = self.patch_embed(hidden_states, grid_thw)
+
+ rotary_pos_emb = self.rot_pos_emb(grid_thw)
+
+ cu_seqlens = torch.repeat_interleave(grid_thw[:, 1] * grid_thw[:, 2], grid_thw[:, 0]).cumsum(
+ dim=0,
+ dtype=grid_thw.dtype if torch.jit.is_tracing() else torch.int32,
+ )
+ cu_seqlens = F.pad(cu_seqlens, (1, 0), value=0)
+
+ for blk in self.blocks:
+ if self.gradient_checkpointing and self.training:
+ hidden_states = self._gradient_checkpointing_func(
+ blk.__call__,
+ hidden_states,
+ cu_seqlens,
+ rotary_pos_emb,
+ use_reentrant=(self.config.ckpt_use_reentrant or self.config.ve_ckpt_use_reentrant),
+ )
+ else:
+ hidden_states = blk(hidden_states, cu_seqlens=cu_seqlens, rotary_pos_emb=rotary_pos_emb)
+
+ if self.config.post_norm:
+ hidden_states = self.post_trunk_norm(hidden_states)
+
+ hidden_states = self.merger(hidden_states)
+ return hidden_states
\ No newline at end of file
diff --git a/preprocessor_config.json b/preprocessor_config.json
new file mode 100644
index 0000000..5786e21
--- /dev/null
+++ b/preprocessor_config.json
@@ -0,0 +1,19 @@
+{
+ "min_pixels": 3136,
+ "max_pixels": 11289600,
+ "patch_size": 14,
+ "temporal_patch_size": 1,
+ "merge_size": 2,
+ "image_mean": [
+ 0.48145466,
+ 0.4578275,
+ 0.40821073
+ ],
+ "image_std": [
+ 0.26862954,
+ 0.26130258,
+ 0.27577711
+ ],
+ "image_processor_type": "Qwen2VLImageProcessor",
+ "processor_class": "DotsVLProcessor"
+}
diff --git a/special_tokens_map.json b/special_tokens_map.json
new file mode 100644
index 0000000..ec36c2f
--- /dev/null
+++ b/special_tokens_map.json
@@ -0,0 +1,25 @@
+{
+ "additional_special_tokens": [
+ "<|im_start|>",
+ "<|im_end|>",
+ "<|object_ref_start|>",
+ "<|object_ref_end|>",
+ "<|box_start|>",
+ "<|box_end|>",
+ "<|quad_start|>",
+ "<|quad_end|>",
+ "<|vision_start|>",
+ "<|vision_end|>",
+ "<|vision_pad|>",
+ "<|image_pad|>",
+ "<|video_pad|>"
+ ],
+ "eos_token": {
+ "content": "<|endoftext|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false
+ },
+ "pad_token": "[PAD]"
+}
diff --git a/tokenizer.json b/tokenizer.json
new file mode 100644
index 0000000..2a7818e
--- /dev/null
+++ b/tokenizer.json
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:386545eb05f08c51352cde2fcc2c867f1592bb330f305efd1c6a57a93b1244cd
+size 7036028
diff --git a/tokenizer_config.json b/tokenizer_config.json
new file mode 100644
index 0000000..a7055e5
--- /dev/null
+++ b/tokenizer_config.json
@@ -0,0 +1,391 @@
+{
+ "add_bos_token": false,
+ "add_prefix_space": false,
+ "added_tokens_decoder": {
+ "151643": {
+ "content": "<|endoftext|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151644": {
+ "content": "<|im_start|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151645": {
+ "content": "<|im_end|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151646": {
+ "content": "<|object_ref_start|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151647": {
+ "content": "<|object_ref_end|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151648": {
+ "content": "<|box_start|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151649": {
+ "content": "<|box_end|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151650": {
+ "content": "<|quad_start|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151651": {
+ "content": "<|quad_end|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151652": {
+ "content": "<|vision_start|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151653": {
+ "content": "<|vision_end|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151654": {
+ "content": "<|vision_pad|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151655": {
+ "content": "<|image_pad|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151656": {
+ "content": "<|video_pad|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151657": {
+ "content": "
+
+
+## Acknowledgments
+We would like to thank [Qwen2.5-VL](https://github.com/QwenLM/Qwen2.5-VL), [aimv2](https://github.com/apple/ml-aim), [MonkeyOCR](https://github.com/Yuliang-Liu/MonkeyOCR),
+[OmniDocBench](https://github.com/opendatalab/OmniDocBench), [PyMuPDF](https://github.com/pymupdf/PyMuPDF), for providing code and models.
+
+We also thank [DocLayNet](https://github.com/DS4SD/DocLayNet), [M6Doc](https://github.com/HCIILAB/M6Doc), [CDLA](https://github.com/buptlihang/CDLA), [D4LA](https://github.com/AlibabaResearch/AdvancedLiterateMachinery) for providing valuable datasets.
+
+## Limitation & Future Work
+
+- **Complex Document Elements:**
+ - **Table&Formula**: dots.ocr is not yet perfect for high-complexity tables and formula extraction.
+ - **Picture**: Pictures in documents are currently not parsed.
+
+- **Parsing Failures:** The model may fail to parse under certain conditions:
+ - When the character-to-pixel ratio is excessively high. Try enlarging the image or increasing the PDF parsing DPI (a setting of 200 is recommended). However, please note that the model performs optimally on images with a resolution under 11289600 pixels.
+ - Continuous special characters, such as ellipses (`...`) and underscores (`_`), may cause the prediction output to repeat endlessly. In such scenarios, consider using alternative prompts like `prompt_layout_only_en`, `prompt_ocr`, or `prompt_grounding_ocr` ([details here](https://github.com/rednote-hilab/dots.ocr/blob/master/dots_ocr/utils/prompts.py)).
+
+- **Performance Bottleneck:** Despite its 1.7B parameter LLM foundation, **dots.ocr** is not yet optimized for high-throughput processing of large PDF volumes.
+
+We are committed to achieving more accurate table and formula parsing, as well as enhancing the model's OCR capabilities for broader generalization, all while aiming for **a more powerful, more efficient model**. Furthermore, we are actively considering the development of **a more general-purpose perception model** based on Vision-Language Models (VLMs), which would integrate general detection, image captioning, and OCR tasks into a unified framework. **Parsing the content of the pictures in the documents** is also a key priority for our future work.
+We believe that collaboration is the key to tackling these exciting challenges. If you are passionate about advancing the frontiers of document intelligence and are interested in contributing to these future endeavors, we would love to hear from you. Please reach out to us via email at: [yanqing4@xiaohongshu.com].
diff --git a/chat_template.json b/chat_template.json
new file mode 100644
index 0000000..87a662f
--- /dev/null
+++ b/chat_template.json
@@ -0,0 +1,3 @@
+{
+ "chat_template": "{% set image_count = namespace(value=0) %}{% set video_count = namespace(value=0) %}{%- for m in messages %}{%- if m.role == 'system' %}{{- '<|system|>' + m.content + '<|endofsystem|>\n' }}{%- elif m.role == 'user' %}{% if m.content is string %}{{- '<|user|>' + m.content + '<|endofuser|>' }}{% else %} {% for content in m.content %}{% if content['type'] == 'image' or 'image' in content or 'image_url' in content %}{% set image_count.value = image_count.value + 1 %}{% if add_vision_id %}Picture {{ image_count.value }}: {% endif %}<|img|><|imgpad|><|endofimg|>{% elif content['type'] == 'video' or 'video' in content %}{% set video_count.value = video_count.value + 1 %}{% if add_vision_id %}Video {{ video_count.value }}: {% endif %}<|img|><|video_pad|><|endofimg|>{% elif 'text' in content %}{{ content['text'] }}{% endif %}{% endfor %}{%- endif %}{%- elif m.role == 'assistant' %}{{- '<|assistant|>' + m.content }}{%- if not loop.last %}{{- '<|endofassistant|>' }}{%- endif %}{%- endif %}{%- endfor %}{%- if messages[-1].role != 'assistant' %}{{- '<|assistant|>' }}{%- endif %}"
+}
\ No newline at end of file
diff --git a/config.json b/config.json
new file mode 100644
index 0000000..7ea2c09
--- /dev/null
+++ b/config.json
@@ -0,0 +1,51 @@
+{
+ "architectures": [
+ "DotsOCRForCausalLM"
+ ],
+ "model_type": "dots_ocr",
+ "auto_map": {
+ "AutoConfig": "configuration_dots.DotsOCRConfig",
+ "AutoModelForCausalLM": "modeling_dots_ocr.DotsOCRForCausalLM"
+ },
+ "attention_bias": true,
+ "attention_dropout": 0.0,
+ "hidden_act": "silu",
+ "hidden_size": 1536,
+ "initializer_range": 0.02,
+ "intermediate_size": 8960,
+ "max_position_embeddings": 131072,
+ "max_window_layers": 28,
+ "num_attention_heads": 12,
+ "num_hidden_layers": 28,
+ "num_key_value_heads": 2,
+ "rms_norm_eps": 1e-06,
+ "rope_scaling": null,
+ "rope_theta": 1000000,
+ "sliding_window": 131072,
+ "tie_word_embeddings": false,
+ "torch_dtype": "bfloat16",
+ "transformers_version": "4.51.0",
+ "use_cache": true,
+ "use_sliding_window": false,
+ "vocab_size": 151936,
+ "image_token_id": 151665,
+ "video_token_id": 151656,
+ "vision_config": {
+ "embed_dim": 1536,
+ "hidden_size": 1536,
+ "intermediate_size": 4224,
+ "num_hidden_layers": 42,
+ "num_attention_heads": 12,
+ "num_channels": 3,
+ "patch_size": 14,
+ "post_norm": true,
+ "rms_norm_eps": 1e-05,
+ "spatial_merge_size": 2,
+ "temporal_patch_size": 1,
+ "use_bias": false,
+ "attn_implementation": "flash_attention_2",
+ "init_merger_std": 0.02,
+ "initializer_range": 0.02,
+ "is_causal": false
+ }
+}
\ No newline at end of file
diff --git a/configuration.json b/configuration.json
new file mode 100644
index 0000000..4aef15d
--- /dev/null
+++ b/configuration.json
@@ -0,0 +1 @@
+{"framework": "pytorch", "task": "image-text-to-text", "allow_remote": true}
\ No newline at end of file
diff --git a/configuration_dots.py b/configuration_dots.py
new file mode 100644
index 0000000..55901c2
--- /dev/null
+++ b/configuration_dots.py
@@ -0,0 +1,76 @@
+from typing import Any, Optional
+from transformers.configuration_utils import PretrainedConfig
+from transformers.models.qwen2 import Qwen2Config
+from transformers import Qwen2_5_VLProcessor, AutoProcessor
+from transformers.models.auto.configuration_auto import CONFIG_MAPPING
+
+
+class DotsVisionConfig(PretrainedConfig):
+ model_type: str = "dots_vit"
+
+ def __init__(
+ self,
+ embed_dim: int = 1536, # vision encoder embed size
+ hidden_size: int = 1536, # after merger hidden size
+ intermediate_size: int = 4224,
+ num_hidden_layers: int = 42,
+ num_attention_heads: int = 12,
+ num_channels: int = 3,
+ patch_size: int = 14,
+ spatial_merge_size: int = 2,
+ temporal_patch_size: int = 1,
+ rms_norm_eps: float = 1e-5,
+ use_bias: bool = False,
+ attn_implementation="flash_attention_2", # "eager","sdpa","flash_attention_2"
+ initializer_range=0.02,
+ init_merger_std=0.02,
+ is_causal=False, # ve causal forward
+ post_norm=True,
+ gradient_checkpointing=False,
+ **kwargs: Any,
+ ):
+ super().__init__(**kwargs)
+ self.embed_dim = embed_dim
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.num_channels = num_channels
+ self.patch_size = patch_size
+ self.spatial_merge_size = spatial_merge_size
+ self.temporal_patch_size = temporal_patch_size
+ self.rms_norm_eps = rms_norm_eps
+ self.use_bias = use_bias
+ self.attn_implementation = attn_implementation
+ self.initializer_range = initializer_range
+ self.init_merger_std = init_merger_std
+ self.is_causal = is_causal
+ self.post_norm = post_norm
+ self.gradient_checkpointing = gradient_checkpointing
+
+
+
+class DotsOCRConfig(Qwen2Config):
+ model_type = "dots_ocr"
+ def __init__(self,
+ image_token_id = 151665,
+ video_token_id = 151656,
+ vision_config: Optional[dict] = None, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.image_token_id = image_token_id
+ self.video_token_id = video_token_id
+ self.vision_config = DotsVisionConfig(**(vision_config or {}))
+
+ def save_pretrained(self, save_directory, **kwargs):
+ self._auto_class = None
+ super().save_pretrained(save_directory, **kwargs)
+
+
+class DotsVLProcessor(Qwen2_5_VLProcessor):
+ def __init__(self, image_processor=None, tokenizer=None, chat_template=None, **kwargs):
+ super().__init__(image_processor, tokenizer, chat_template=chat_template)
+ self.image_token = "<|imgpad|>" if not hasattr(tokenizer, "image_token") else tokenizer.image_token
+
+
+AutoProcessor.register("dots_ocr", DotsVLProcessor)
+CONFIG_MAPPING.register("dots_ocr", DotsOCRConfig)
diff --git a/generation_config.json b/generation_config.json
new file mode 100644
index 0000000..c6f6906
--- /dev/null
+++ b/generation_config.json
@@ -0,0 +1,7 @@
+{
+ "max_length": 32768,
+ "eos_token_id": [
+ 151643,
+ 151673
+ ]
+}
diff --git a/merges.txt b/merges.txt
new file mode 100644
index 0000000..7ce1d95
--- /dev/null
+++ b/merges.txt
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:599bab54075088774b1733fde865d5bd747cbcc7a547c5bc12610e874e26f5e3
+size 1671839
diff --git a/model-00001-of-00002.safetensors b/model-00001-of-00002.safetensors
new file mode 100644
index 0000000..6a5014f
--- /dev/null
+++ b/model-00001-of-00002.safetensors
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:686da8b6a33f88d4fc83092a1f601dbb12ca4e639942190771a61f5cc287aa24
+size 135
diff --git a/model-00002-of-00002.safetensors b/model-00002-of-00002.safetensors
new file mode 100644
index 0000000..09e3c4a
--- /dev/null
+++ b/model-00002-of-00002.safetensors
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8d00568ee09e48f30b2ebd2b2245f6fa07bb2e1afcc3c0300f8298d6a52abf49
+size 135
diff --git a/model.safetensors.index.json b/model.safetensors.index.json
new file mode 100644
index 0000000..8a62c07
--- /dev/null
+++ b/model.safetensors.index.json
@@ -0,0 +1,650 @@
+{
+ "metadata": {
+ "total_size": 6078358528
+ },
+ "weight_map": {
+ "lm_head.weight": "model-00001-of-00002.safetensors",
+ "model.embed_tokens.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.0.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.0.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.0.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.0.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.1.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.1.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.1.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.1.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.10.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.10.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.10.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.10.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.11.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.11.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.11.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.11.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.12.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.12.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.12.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.12.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.13.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.13.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.13.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.13.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.14.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.14.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.14.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.14.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.15.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.15.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.15.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.15.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.16.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.16.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.16.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.16.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.17.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.17.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.17.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.17.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.18.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.18.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.18.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.18.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.19.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.19.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.19.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.19.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.2.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.2.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.2.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.2.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.20.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.20.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.20.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.20.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.21.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.21.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.21.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.21.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.22.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.22.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.22.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.22.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.23.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.23.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.23.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.23.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.24.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.24.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.24.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.24.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.25.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.25.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.25.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.25.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.26.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.26.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.26.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.26.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.27.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.27.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.27.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.27.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.3.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.3.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.3.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.3.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.4.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.4.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.4.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.4.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.5.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.5.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.5.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.5.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.6.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.6.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.6.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.6.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.7.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.7.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.7.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.7.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.8.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.8.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.8.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.8.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.input_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.9.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.9.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
+ "model.layers.9.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
+ "model.layers.9.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
+ "model.norm.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.0.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.0.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.0.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.0.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.0.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.0.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.0.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.1.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.1.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.1.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.1.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.1.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.1.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.1.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.10.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.10.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.10.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.10.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.10.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.10.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.10.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.11.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.11.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.11.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.11.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.11.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.11.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.11.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.12.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.12.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.12.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.12.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.12.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.12.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.12.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.13.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.13.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.13.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.13.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.13.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.13.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.13.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.14.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.14.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.14.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.14.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.14.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.14.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.14.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.15.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.15.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.15.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.15.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.15.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.15.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.15.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.16.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.16.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.16.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.16.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.16.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.16.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.16.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.17.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.17.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.17.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.17.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.17.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.17.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.17.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.18.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.18.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.18.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.18.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.18.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.18.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.18.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.19.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.19.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.19.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.19.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.19.mlp.fc3.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.19.norm1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.19.norm2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.2.attn.proj.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.2.attn.qkv.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.2.mlp.fc1.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.2.mlp.fc2.weight": "model-00001-of-00002.safetensors",
+ "vision_tower.blocks.2.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.2.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.2.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.20.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.20.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.20.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.20.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.20.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.20.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.20.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.21.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.21.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.21.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.21.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.21.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.21.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.21.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.22.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.22.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.22.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.22.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.22.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.22.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.22.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.23.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.23.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.23.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.23.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.23.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.23.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.23.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.24.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.24.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.24.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.24.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.24.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.24.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.24.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.25.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.25.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.25.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.25.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.25.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.25.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.25.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.26.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.26.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.26.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.26.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.26.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.26.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.26.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.27.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.27.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.27.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.27.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.27.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.27.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.27.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.28.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.28.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.28.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.28.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.28.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.28.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.28.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.29.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.29.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.29.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.29.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.29.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.29.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.29.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.3.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.3.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.3.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.3.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.3.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.3.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.3.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.30.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.30.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.30.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.30.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.30.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.30.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.30.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.31.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.31.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.31.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.31.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.31.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.31.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.31.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.32.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.32.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.32.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.32.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.32.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.32.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.32.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.33.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.33.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.33.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.33.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.33.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.33.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.33.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.34.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.34.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.34.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.34.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.34.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.34.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.34.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.35.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.35.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.35.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.35.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.35.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.35.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.35.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.36.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.36.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.36.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.36.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.36.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.36.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.36.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.37.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.37.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.37.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.37.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.37.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.37.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.37.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.38.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.38.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.38.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.38.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.38.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.38.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.38.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.39.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.39.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.39.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.39.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.39.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.39.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.39.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.4.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.4.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.4.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.4.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.4.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.4.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.4.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.40.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.40.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.40.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.40.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.40.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.40.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.40.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.41.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.41.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.41.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.41.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.41.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.41.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.41.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.5.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.5.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.5.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.5.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.5.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.5.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.5.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.6.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.6.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.6.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.6.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.6.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.6.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.6.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.7.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.7.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.7.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.7.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.7.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.7.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.7.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.8.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.8.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.8.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.8.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.8.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.8.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.8.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.9.attn.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.9.attn.qkv.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.9.mlp.fc1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.9.mlp.fc2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.9.mlp.fc3.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.9.norm1.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.blocks.9.norm2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.merger.ln_q.bias": "model-00002-of-00002.safetensors",
+ "vision_tower.merger.ln_q.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.merger.mlp.0.bias": "model-00002-of-00002.safetensors",
+ "vision_tower.merger.mlp.0.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.merger.mlp.2.bias": "model-00002-of-00002.safetensors",
+ "vision_tower.merger.mlp.2.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.patch_embed.patchifier.norm.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.patch_embed.patchifier.proj.bias": "model-00002-of-00002.safetensors",
+ "vision_tower.patch_embed.patchifier.proj.weight": "model-00002-of-00002.safetensors",
+ "vision_tower.post_trunk_norm.weight": "model-00002-of-00002.safetensors"
+ }
+}
\ No newline at end of file
diff --git a/modeling_dots_ocr.py b/modeling_dots_ocr.py
new file mode 100644
index 0000000..79d1c25
--- /dev/null
+++ b/modeling_dots_ocr.py
@@ -0,0 +1,131 @@
+from typing import List, Optional, Tuple, Union
+
+import torch
+from transformers.modeling_outputs import CausalLMOutputWithPast
+from transformers.models.qwen2 import Qwen2ForCausalLM
+
+from .configuration_dots import DotsVisionConfig, DotsOCRConfig
+from .modeling_dots_vision import DotsVisionTransformer
+
+
+DOTS_VLM_MAX_IMAGES = 200
+
+
+class DotsOCRForCausalLM(Qwen2ForCausalLM):
+ config_class = DotsOCRConfig
+
+ def __init__(self, config: DotsOCRConfig):
+ super().__init__(config)
+
+ if isinstance(self.config.vision_config, dict):
+ vision_config = DotsVisionConfig(**self.config.vision_config)
+ self.config.vision_config = vision_config
+ else:
+ vision_config = self.config.vision_config
+
+ self.vision_tower = DotsVisionTransformer(vision_config)
+
+ def prepare_inputs_embeds(
+ self,
+ input_ids: torch.LongTensor,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ grid_thw: Optional[torch.FloatTensor] = None,
+ img_mask: Optional[torch.BoolTensor] = None,
+ ) -> torch.Tensor:
+ inputs_embeds = self.get_input_embeddings()(input_ids)
+
+ if pixel_values is not None:
+ assert img_mask is not None
+ if grid_thw.shape[0] > DOTS_VLM_MAX_IMAGES:
+ print(
+ f"Num image exceeded: {grid_thw.shape[0]} > {DOTS_VLM_MAX_IMAGES}, which may cause FSDP hang"
+ )
+
+ vision_embeddings = self.vision_tower(pixel_values, grid_thw)
+
+ true_indices = torch.nonzero(img_mask).squeeze()
+ if len(true_indices) > vision_embeddings.size(0):
+ print(
+ f"img_mask sum > VE and will be truncated, mask.sum()={len(true_indices)} {vision_embeddings.size(0)=}"
+ )
+ true_indices = true_indices[: vision_embeddings.size(0)]
+ new_img_mask = torch.zeros_like(img_mask, device=img_mask.device)
+ new_img_mask[true_indices[:, 0], true_indices[:, 1]] = True
+ else:
+ new_img_mask = img_mask
+
+ assert (
+ vision_embeddings.size(0) == new_img_mask.sum()
+ ), f"{vision_embeddings.size(0)=}, {new_img_mask.sum()=}"
+
+ inputs_embeds = inputs_embeds.masked_scatter(
+ new_img_mask.to(inputs_embeds.device).unsqueeze(-1).expand_as(inputs_embeds),
+ vision_embeddings.to(inputs_embeds.device).type(inputs_embeds.dtype),
+ )
+
+ return inputs_embeds
+
+ def forward(
+ self,
+ input_ids: torch.LongTensor,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ image_grid_thw: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ use_cache: Optional[bool] = None,
+ logits_to_keep: int = 0,
+ **loss_kwargs,
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ assert len(input_ids) >= 1, f"empty input_ids {input_ids.shape=} will cause gradnorm nan"
+ if inputs_embeds is None:
+ img_mask = input_ids == self.config.image_token_id
+ inputs_embeds = self.prepare_inputs_embeds(input_ids, pixel_values, image_grid_thw, img_mask)
+
+ outputs = super().forward(
+ inputs_embeds=inputs_embeds,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ labels=labels,
+ use_cache=use_cache if use_cache is not None else self.config.use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ # return_dict=return_dict,
+ logits_to_keep=logits_to_keep,
+ **loss_kwargs,
+ )
+
+ return outputs
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ inputs_embeds=None,
+ pixel_values=None,
+ attention_mask=None,
+ cache_position=None,
+ num_logits_to_keep=None,
+ **kwargs,
+ ):
+ model_inputs = super().prepare_inputs_for_generation(
+ input_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ attention_mask=attention_mask,
+ cache_position=cache_position,
+ num_logits_to_keep=num_logits_to_keep,
+ **kwargs,
+ )
+
+ if cache_position[0] == 0:
+ model_inputs["pixel_values"] = pixel_values
+
+ return model_inputs
diff --git a/modeling_dots_ocr_vllm.py b/modeling_dots_ocr_vllm.py
new file mode 100644
index 0000000..07195e8
--- /dev/null
+++ b/modeling_dots_ocr_vllm.py
@@ -0,0 +1,429 @@
+from functools import cached_property
+from typing import Iterable, Literal, Mapping, Optional, Set, Tuple, TypedDict, Union
+
+import torch
+import torch.nn as nn
+from transformers.models.qwen2_vl import Qwen2VLImageProcessor, Qwen2VLProcessor
+from transformers.models.qwen2_vl.image_processing_qwen2_vl import smart_resize
+from vllm import ModelRegistry
+from vllm.config import VllmConfig
+from vllm.model_executor.layers.sampler import SamplerOutput, get_sampler
+from vllm.model_executor.models.interfaces import MultiModalEmbeddings, SupportsMultiModal
+from vllm.model_executor.models.qwen2 import Qwen2ForCausalLM
+from vllm.model_executor.models.qwen2_5_vl import (
+ Qwen2_5_VLMultiModalProcessor,
+ Qwen2_5_VLProcessingInfo,
+)
+from vllm.model_executor.models.qwen2_vl import Qwen2VLDummyInputsBuilder
+from vllm.model_executor.models.utils import (
+ AutoWeightsLoader,
+ WeightsMapper,
+ init_vllm_registered_model,
+ maybe_prefix,
+ merge_multimodal_embeddings,
+)
+from vllm.model_executor.sampling_metadata import SamplingMetadata
+from vllm.multimodal import MULTIMODAL_REGISTRY
+from vllm.multimodal.inputs import MultiModalDataDict
+from vllm.multimodal.parse import ImageSize
+from vllm.sequence import IntermediateTensors
+
+from .configuration_dots import DotsVisionConfig
+from .configuration_dots import DotsOCRConfig
+from .modeling_dots_vision import DotsVisionTransformer
+
+
+class DotsOCRImagePixelInputs(TypedDict):
+ type: Literal["pixel_values", "image_grid_thw"]
+
+ pixel_values: torch.Tensor
+ image_grid_thw: torch.Tensor
+
+
+class DotsOCRImageEmbeddingInputs(TypedDict):
+ type: Literal["image_embeds", "image_grid_thw"]
+ image_embeds: torch.Tensor
+ """Supported types:
+ - List[`torch.Tensor`]: A list of tensors holding all images' features.
+ Each tensor holds an image's features.
+ - `torch.Tensor`: A tensor holding all images' features
+ (concatenation of all images' feature tensors).
+
+ Tensor shape: `(num_image_features, hidden_size)`
+ - `num_image_features` varies based on
+ the number and resolution of the images.
+ - `hidden_size` must match the hidden size of language model backbone.
+ """
+
+ image_grid_thw: torch.Tensor
+
+
+DotsOCRImageInputs = Union[DotsOCRImagePixelInputs, DotsOCRImageEmbeddingInputs]
+
+
+class DotsOCRMultiModalProcessor(Qwen2_5_VLMultiModalProcessor):
+ pass
+
+
+class DotsOCRDummyInputsBuilder(Qwen2VLDummyInputsBuilder):
+ def get_dummy_mm_data(
+ self,
+ seq_len: int,
+ mm_counts: Mapping[str, int],
+ ) -> MultiModalDataDict:
+ num_images = mm_counts.get("image", 0)
+
+ target_width, target_height = self.info.get_image_size_with_most_features()
+
+ return {
+ "image": self._get_dummy_images(width=target_width, height=target_height, num_images=num_images),
+ }
+
+
+class DotsOCRProcessingInfo(Qwen2_5_VLProcessingInfo):
+ def get_hf_config(self) -> DotsOCRConfig:
+ config = self.ctx.get_hf_config()
+ if not config.__class__.__name__ == 'DotsOCRConfig':
+ raise TypeError(f"Expected DotsOCRConfig, got {type(config)}")
+
+ if hasattr(config, "vision_config") and isinstance(config.vision_config, dict):
+ config.vision_config = DotsVisionConfig(**config.vision_config)
+
+ return config
+
+ def get_hf_processor(
+ self,
+ *,
+ min_pixels: Optional[int] = None,
+ max_pixels: Optional[int] = None,
+ size: Optional[dict[str, int]] = None,
+ **kwargs: object,
+ ) -> Qwen2VLProcessor:
+ processor = self.ctx.get_hf_processor(
+ Qwen2VLProcessor,
+ image_processor=self.get_image_processor(min_pixels=min_pixels, max_pixels=max_pixels, size=size),
+ **kwargs,
+ )
+ processor.image_token = "<|imgpad|>"
+ processor.video_token = "<|video_pad|>"
+ return processor
+
+ def _get_vision_info(
+ self,
+ *,
+ image_width: int,
+ image_height: int,
+ num_frames: int = 1,
+ do_resize: bool = True,
+ image_processor: Optional[Qwen2VLImageProcessor],
+ ) -> tuple[ImageSize, int]:
+ if image_processor is None:
+ image_processor = self.get_image_processor()
+
+ hf_config: DotsOCRConfig = self.get_hf_config()
+ vision_config = hf_config.vision_config
+ patch_size = vision_config.patch_size
+ merge_size = vision_config.spatial_merge_size
+ temporal_patch_size = vision_config.temporal_patch_size
+
+ if do_resize:
+ resized_height, resized_width = smart_resize(
+ height=image_height,
+ width=image_width,
+ factor=patch_size * merge_size,
+ min_pixels=image_processor.min_pixels,
+ max_pixels=image_processor.max_pixels,
+ )
+ preprocessed_size = ImageSize(width=resized_width, height=resized_height)
+ else:
+ preprocessed_size = ImageSize(width=image_width, height=image_height)
+
+ # NOTE: Frames are padded to be divisible by `temporal_patch_size`
+ # https://github.com/huggingface/transformers/blob/v4.48.3/src/transformers/models/qwen2_vl/image_processing_qwen2_vl.py#L294
+ padded_num_frames = num_frames + num_frames % temporal_patch_size
+
+ grid_t = max(padded_num_frames // temporal_patch_size, 1)
+ grid_h = preprocessed_size.height // patch_size
+ grid_w = preprocessed_size.width // patch_size
+
+ num_patches = grid_t * grid_h * grid_w
+ num_vision_tokens = num_patches // (merge_size**2)
+
+ return preprocessed_size, num_vision_tokens
+
+
+@MULTIMODAL_REGISTRY.register_processor(
+ Qwen2_5_VLMultiModalProcessor,
+ info=DotsOCRProcessingInfo,
+ dummy_inputs=DotsOCRDummyInputsBuilder,
+)
+class DotsOCRForCausalLM(nn.Module, SupportsMultiModal):
+ hf_to_vllm_mapper = WeightsMapper(
+ orig_to_new_prefix={
+ "lm_head.": "language_model.lm_head.",
+ "model.": "language_model.model.",
+ }
+ )
+ _tp_plan = {}
+
+ def __init__(self, *, vllm_config: VllmConfig, prefix: str = ""):
+ super().__init__()
+
+ self.config: DotsOCRConfig = vllm_config.model_config.hf_config
+ self.quant_config = vllm_config.quant_config
+ self.multimodal_config = vllm_config.model_config.multimodal_config
+
+ if isinstance(self.config.vision_config, dict):
+ vision_config = DotsVisionConfig(**self.config.vision_config)
+ self.config.vision_config = vision_config
+ else:
+ vision_config = self.config.vision_config
+
+ self.vision_tower = DotsVisionTransformer(vision_config)
+ self.language_model: Qwen2ForCausalLM = init_vllm_registered_model(
+ vllm_config=vllm_config,
+ hf_config=self.config,
+ prefix=maybe_prefix(prefix, "language_model"),
+ architectures=["Qwen2ForCausalLM"],
+ )
+
+ @cached_property
+ def sampler(self):
+ if hasattr(self.language_model, "sampler"):
+ return self.language_model.sampler
+
+ return get_sampler()
+
+ def _validate_and_reshape_mm_tensor(self, mm_input: object, name: str) -> torch.Tensor:
+ if not isinstance(mm_input, (torch.Tensor, list)):
+ raise ValueError(f"Incorrect type of {name}. " f"Got type: {type(mm_input)}")
+ if isinstance(mm_input, torch.Tensor):
+ if mm_input.ndim == 2:
+ return mm_input
+ if mm_input.ndim != 3:
+ raise ValueError(
+ f"{name} should be 2D or batched 3D tensor. "
+ f"Got ndim: {mm_input.ndim} "
+ f"(shape={mm_input.shape})"
+ )
+ return torch.concat(list(mm_input))
+ else:
+ return torch.concat(mm_input)
+
+ def _parse_and_validate_image_input(self, **kwargs: object) -> Optional[DotsOCRImageInputs]:
+ pixel_values = kwargs.pop("pixel_values", None)
+ image_embeds = kwargs.pop("image_embeds", None)
+ image_grid_thw = kwargs.pop("image_grid_thw", None)
+
+ if pixel_values is None and image_embeds is None:
+ return None
+
+ if pixel_values is not None:
+ pixel_values = self._validate_and_reshape_mm_tensor(pixel_values, "image pixel values")
+ image_grid_thw = self._validate_and_reshape_mm_tensor(image_grid_thw, "image grid_thw")
+
+ if not isinstance(pixel_values, (torch.Tensor, list)):
+ raise ValueError("Incorrect type of image pixel values. " f"Got type: {type(pixel_values)}")
+
+ return DotsOCRImagePixelInputs(
+ type="pixel_values", pixel_values=pixel_values, image_grid_thw=image_grid_thw
+ )
+
+ if image_embeds is not None:
+ image_embeds = self._validate_and_reshape_mm_tensor(image_embeds, "image embeds")
+ image_grid_thw = self._validate_and_reshape_mm_tensor(image_grid_thw, "image grid_thw")
+
+ if not isinstance(image_embeds, torch.Tensor):
+ raise ValueError("Incorrect type of image embeddings. " f"Got type: {type(image_embeds)}")
+ return DotsOCRImageEmbeddingInputs(
+ type="image_embeds", image_embeds=image_embeds, image_grid_thw=image_grid_thw
+ )
+
+ def vision_forward(self, pixel_values: torch.Tensor, image_grid_thw: torch.Tensor):
+ from vllm.distributed import (
+ get_tensor_model_parallel_group,
+ get_tensor_model_parallel_rank,
+ get_tensor_model_parallel_world_size,
+ )
+
+ assert self.vision_tower is not None
+
+ tp_rank = get_tensor_model_parallel_rank()
+ tp = get_tensor_model_parallel_world_size()
+
+ image_grid_thw_chunk = image_grid_thw.chunk(tp)
+ image_sizes_consum = torch.tensor([i.prod(-1).sum() for i in image_grid_thw_chunk]).cumsum(dim=0)
+ merge_size_square = self.vision_tower.config.spatial_merge_size**2
+ image_embedding = torch.zeros(
+ (
+ pixel_values.shape[0] // merge_size_square,
+ self.vision_tower.config.hidden_size,
+ ),
+ device=pixel_values.device,
+ dtype=pixel_values.dtype,
+ )
+
+ if tp_rank < len(image_sizes_consum):
+ idx_start = 0 if tp_rank == 0 else image_sizes_consum[tp_rank - 1].item()
+ idx_end = image_sizes_consum[tp_rank].item()
+ pixel_values_part = pixel_values[idx_start:idx_end]
+ image_grid_thw_part = image_grid_thw_chunk[tp_rank]
+ image_embedding_part = self.vision_tower(pixel_values_part, image_grid_thw_part)
+ image_embedding[idx_start // merge_size_square : idx_end // merge_size_square] = image_embedding_part
+
+ group = get_tensor_model_parallel_group().device_group
+ torch.distributed.all_reduce(image_embedding, group=group)
+ return image_embedding
+
+ def _process_image_input(self, image_input: DotsOCRImageInputs) -> tuple[torch.Tensor, ...]:
+ grid_thw = image_input["image_grid_thw"]
+ assert grid_thw.ndim == 2
+
+ if image_input["type"] == "image_embeds":
+ image_embeds = image_input["image_embeds"].type(self.vision_tower.dtype)
+ else:
+ pixel_values = image_input["pixel_values"].type(self.vision_tower.dtype)
+ image_embeds = self.vision_forward(pixel_values, grid_thw)[
+ :, : self.config.hidden_size
+ ]
+
+ # Split concatenated embeddings for each image item.
+ merge_size = self.vision_tower.config.spatial_merge_size
+ sizes = grid_thw.prod(-1) // merge_size // merge_size
+
+ return image_embeds.split(sizes.tolist())
+
+ def _parse_and_validate_multimodal_inputs(self, **kwargs: object) -> dict:
+ modalities = {}
+
+ # Preserve the order of modalities if there are multiple of them
+ # from the order of kwargs.
+ for input_key in kwargs:
+ if input_key in ("pixel_values", "image_embeds") and "images" not in modalities:
+ modalities["images"] = self._parse_and_validate_image_input(**kwargs)
+ return modalities
+
+ def get_language_model(self) -> torch.nn.Module:
+ return self.language_model
+
+ def get_multimodal_embeddings(self, **kwargs: object) -> Optional[MultiModalEmbeddings]:
+ modalities = self._parse_and_validate_multimodal_inputs(**kwargs)
+ if not modalities:
+ return None
+
+ # The result multimodal_embeddings is tuple of tensors, with each
+ # tensor correspoending to a multimodal data item (image or video).
+ multimodal_embeddings: tuple[torch.Tensor, ...] = ()
+
+ # NOTE: It is important to iterate over the keys in this dictionary
+ # to preserve the order of the modalities.
+ for modality in modalities:
+ if modality == "images":
+ image_input = modalities["images"]
+ vision_embeddings = self._process_image_input(image_input)
+ multimodal_embeddings += vision_embeddings
+
+ return multimodal_embeddings
+
+ def get_input_embeddings(
+ self,
+ input_ids: torch.Tensor,
+ multimodal_embeddings: Optional[MultiModalEmbeddings] = None,
+ ) -> torch.Tensor:
+ inputs_embeds = self.language_model.get_input_embeddings(input_ids)
+ if multimodal_embeddings is not None:
+ inputs_embeds = merge_multimodal_embeddings(
+ input_ids,
+ inputs_embeds,
+ multimodal_embeddings,
+ [self.config.image_token_id, self.config.video_token_id],
+ )
+
+ return inputs_embeds
+
+ def get_input_embeddings_v0(
+ self,
+ input_ids: torch.Tensor,
+ image_input: Optional[DotsOCRImagePixelInputs] = None,
+ ) -> torch.Tensor:
+ inputs_embeds = self.get_input_embeddings(input_ids)
+ if image_input is not None:
+ image_embeds = self._process_image_input(image_input)
+ inputs_embeds = merge_multimodal_embeddings(
+ input_ids,
+ inputs_embeds,
+ image_embeds,
+ placeholder_token_id=self.config.image_token_id,
+ )
+ return inputs_embeds
+
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor],
+ positions: torch.Tensor,
+ intermediate_tensors: Optional[IntermediateTensors] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ **kwargs,
+ ) -> Union[torch.Tensor, IntermediateTensors]:
+ if intermediate_tensors is not None:
+ inputs_embeds = None
+ elif inputs_embeds is None and kwargs.get("pixel_values") is not None:
+ image_input = self._parse_and_validate_image_input(**kwargs)
+ if image_input is None:
+ inputs_embeds = None
+ else:
+ assert input_ids is not None
+ inputs_embeds = self.get_input_embeddings_v0(
+ input_ids,
+ image_input=image_input,
+ )
+ input_ids = None
+
+ hidden_states = self.language_model(
+ input_ids=input_ids,
+ positions=positions,
+ intermediate_tensors=intermediate_tensors,
+ inputs_embeds=inputs_embeds,
+ )
+
+ return hidden_states
+
+ def compute_logits(
+ self,
+ hidden_states: torch.Tensor,
+ sampling_metadata: SamplingMetadata,
+ ) -> Optional[torch.Tensor]:
+ return self.language_model.compute_logits(hidden_states, sampling_metadata)
+
+ def sample(
+ self,
+ logits: Optional[torch.Tensor],
+ sampling_metadata: SamplingMetadata,
+ ) -> Optional[SamplerOutput]:
+ next_tokens = self.sampler(logits, sampling_metadata)
+ return next_tokens
+
+ def load_weights(self, weights: Iterable[Tuple[str, torch.Tensor]]) -> Set[str]:
+ loader = AutoWeightsLoader(self)
+ return loader.load_weights(weights, mapper=self.hf_to_vllm_mapper)
+
+
+def patch_vllm_chat_placeholder():
+ from vllm.entrypoints.chat_utils import BaseMultiModalItemTracker
+
+ ori = BaseMultiModalItemTracker._placeholder_str
+
+ def _placeholder_str(self, modality, current_count: int) -> Optional[str]:
+ hf_config = self._model_config.hf_config
+ model_type = hf_config.model_type
+ if modality in ("image",) and model_type in ["dots_ocr"]:
+ return "<|img|><|imgpad|><|endofimg|>"
+ return ori(self, modality, current_count)
+
+ BaseMultiModalItemTracker._placeholder_str = _placeholder_str
+
+ModelRegistry.register_model(
+ "DotsOCRForCausalLM", DotsOCRForCausalLM,
+)
+
+patch_vllm_chat_placeholder()
\ No newline at end of file
diff --git a/modeling_dots_vision.py b/modeling_dots_vision.py
new file mode 100644
index 0000000..62a1bdf
--- /dev/null
+++ b/modeling_dots_vision.py
@@ -0,0 +1,405 @@
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from flash_attn import flash_attn_varlen_func
+from torch.nn import LayerNorm
+from transformers.modeling_utils import PreTrainedModel
+from .configuration_dots import DotsVisionConfig
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb_vision(tensor: torch.Tensor, freqs: torch.Tensor) -> torch.Tensor:
+ orig_dtype = tensor.dtype
+ tensor = tensor.float()
+
+ cos = freqs.cos()
+ sin = freqs.sin()
+
+ cos = cos.unsqueeze(1).repeat(1, 1, 2).unsqueeze(0).float()
+ sin = sin.unsqueeze(1).repeat(1, 1, 2).unsqueeze(0).float()
+
+ output = (tensor * cos) + (rotate_half(tensor) * sin)
+
+ output = output.to(orig_dtype)
+
+ return output
+
+
+class VisionRotaryEmbedding(nn.Module):
+ def __init__(self, dim: int, theta: float = 10000.0) -> None:
+ super().__init__()
+ inv_freq = 1.0 / (theta ** (torch.arange(0, dim, 2, dtype=torch.float) / dim))
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+
+ def forward(self, seqlen: int) -> torch.Tensor:
+ seq = torch.arange(seqlen, device=self.inv_freq.device, dtype=self.inv_freq.dtype)
+ freqs = torch.outer(seq, self.inv_freq)
+ return freqs
+
+
+class PatchMerger(nn.Module):
+ def __init__(
+ self,
+ dim: int,
+ context_dim: int,
+ spatial_merge_size: int = 2,
+ pre_norm="layernorm",
+ init_merger_std=None,
+ ) -> None:
+ super().__init__()
+ self.hidden_size = context_dim * (spatial_merge_size**2)
+ self.pre_norm = pre_norm
+ if self.pre_norm == "layernorm":
+ self.ln_q = LayerNorm(context_dim, eps=1e-6)
+ elif self.pre_norm == "rmsnorm":
+ self.ln_q = RMSNorm(context_dim, eps=1e-6)
+ else:
+ print("no norm in patch merger")
+
+ self.mlp = nn.Sequential(
+ nn.Linear(self.hidden_size, self.hidden_size),
+ nn.GELU(),
+ nn.Linear(self.hidden_size, dim),
+ )
+
+ if init_merger_std is not None:
+ nn.init.normal_(self.mlp[0].weight, mean=0.0, std=init_merger_std)
+ nn.init.zeros_(self.mlp[0].bias)
+ nn.init.normal_(self.mlp[2].weight, mean=0.0, std=init_merger_std)
+ nn.init.zeros_(self.mlp[2].bias)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ if self.pre_norm:
+ x = self.mlp(self.ln_q(x).view(-1, self.hidden_size))
+ else:
+ x = self.mlp(x.view(-1, self.hidden_size))
+ return x
+
+
+class VisionAttention(nn.Module):
+ def __init__(self, config, dim: int, num_heads: int = 16, bias=True) -> None:
+ super().__init__()
+ self.num_heads = num_heads
+ self.head_dim = dim // num_heads
+ self.qkv = nn.Linear(dim, dim * 3, bias=bias)
+ self.proj = nn.Linear(dim, dim, bias=bias)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ cu_seqlens: torch.Tensor,
+ rotary_pos_emb: torch.Tensor = None,
+ ) -> torch.Tensor:
+ seq_length = hidden_states.shape[0]
+
+ q, k, v = self.qkv(hidden_states).reshape(seq_length, 3, self.num_heads, -1).permute(1, 0, 2, 3).unbind(0)
+ q = apply_rotary_pos_emb_vision(q.unsqueeze(0), rotary_pos_emb).squeeze(0)
+ k = apply_rotary_pos_emb_vision(k.unsqueeze(0), rotary_pos_emb).squeeze(0)
+
+ attention_mask = torch.full(
+ [1, seq_length, seq_length], torch.finfo(q.dtype).min, device=q.device, dtype=q.dtype
+ )
+ for i in range(1, len(cu_seqlens)):
+ attention_mask[..., cu_seqlens[i - 1] : cu_seqlens[i], cu_seqlens[i - 1] : cu_seqlens[i]] = 0
+
+ q = q.transpose(0, 1)
+ k = k.transpose(0, 1)
+ v = v.transpose(0, 1)
+ attn_weights = torch.matmul(q, k.transpose(1, 2)) / math.sqrt(self.head_dim)
+ attn_weights = attn_weights + attention_mask
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(q.dtype)
+ attn_output = torch.matmul(attn_weights, v)
+ attn_output = attn_output.transpose(0, 1)
+ attn_output = attn_output.reshape(seq_length, -1)
+ attn_output = self.proj(attn_output)
+ return attn_output
+
+
+class VisionFlashAttention2(nn.Module):
+ def __init__(self, config, dim: int, num_heads: int = 16, bias=True) -> None:
+ super().__init__()
+ self.num_heads = num_heads
+ self.qkv = nn.Linear(dim, dim * 3, bias=bias)
+ self.proj = nn.Linear(dim, dim, bias=bias)
+ self.config = config
+ self.is_causal = config.is_causal
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ cu_seqlens: torch.Tensor,
+ rotary_pos_emb: torch.Tensor = None,
+ ) -> torch.Tensor:
+ seq_length = hidden_states.shape[0]
+ q, k, v = (
+ self.qkv(hidden_states).reshape(seq_length, 3, self.num_heads, -1).permute(1, 0, 2, 3).unbind(0)
+ ) # 'shd'
+ q = apply_rotary_pos_emb_vision(q.unsqueeze(0), rotary_pos_emb).squeeze(0)
+ k = apply_rotary_pos_emb_vision(k.unsqueeze(0), rotary_pos_emb).squeeze(0)
+ max_seqlen = (cu_seqlens[1:] - cu_seqlens[:-1]).max().item()
+ attn_output = flash_attn_varlen_func(
+ q, k, v, cu_seqlens, cu_seqlens, max_seqlen, max_seqlen, causal=self.is_causal
+ ).reshape(seq_length, -1)
+ attn_output = self.proj(attn_output)
+
+ return attn_output
+
+
+class VisionSdpaAttention(nn.Module):
+ def __init__(self, config, dim: int, num_heads: int = 16, bias=True) -> None:
+ super().__init__()
+ self.num_heads = num_heads
+ self.qkv = nn.Linear(dim, dim * 3, bias=bias)
+ self.proj = nn.Linear(dim, dim, bias=bias)
+ self.config = config
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ cu_seqlens: torch.Tensor,
+ rotary_pos_emb: torch.Tensor = None,
+ ) -> torch.Tensor:
+ seq_length = hidden_states.shape[0]
+ q, k, v = self.qkv(hidden_states).reshape(seq_length, 3, self.num_heads, -1).permute(1, 0, 2, 3).unbind(0)
+
+ q = apply_rotary_pos_emb_vision(q.unsqueeze(0), rotary_pos_emb).squeeze(0)
+ k = apply_rotary_pos_emb_vision(k.unsqueeze(0), rotary_pos_emb).squeeze(0)
+
+ attention_mask = torch.zeros([1, seq_length, seq_length], device=q.device, dtype=torch.bool)
+ for i in range(1, len(cu_seqlens)):
+ attention_mask[..., cu_seqlens[i - 1] : cu_seqlens[i], cu_seqlens[i - 1] : cu_seqlens[i]] = True
+
+ q = q.transpose(0, 1)
+ k = k.transpose(0, 1)
+ v = v.transpose(0, 1)
+
+ attn_output = F.scaled_dot_product_attention(q, k, v, attention_mask, dropout_p=0.0)
+ attn_output = attn_output.transpose(0, 1)
+ attn_output = attn_output.reshape(seq_length, -1)
+
+ attn_output = self.proj(attn_output)
+ return attn_output
+
+
+DOTS_VISION_ATTENTION_CLASSES = {
+ "eager": VisionAttention,
+ "flash_attention_2": VisionFlashAttention2,
+ "sdpa": VisionSdpaAttention,
+}
+
+
+class RMSNorm(nn.Module):
+ def __init__(self, dim: int, eps: float = 1e-6):
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(dim))
+ self.eps = eps
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ output = self._norm(x.float()).type_as(x)
+ return output * self.weight
+
+ def extra_repr(self) -> str:
+ return f"{tuple(self.weight.shape)}, eps={self.eps}"
+
+ def _norm(self, x: torch.Tensor) -> torch.Tensor:
+ return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
+
+
+class DotsSwiGLUFFN(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ hidden_features = config.intermediate_size
+ in_features = config.embed_dim
+ bias = config.use_bias
+
+ self.fc1 = nn.Linear(in_features, hidden_features, bias=bias)
+ self.fc2 = nn.Linear(hidden_features, in_features, bias=bias)
+ self.fc3 = nn.Linear(in_features, hidden_features, bias=bias)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ x = F.silu(self.fc1(x)) * self.fc3(x)
+ x = self.fc2(x)
+ return x
+
+
+
+class DotsPatchEmbed(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.num_channels = config.num_channels
+ self.patch_size = config.patch_size
+ self.temporal_patch_size = config.temporal_patch_size
+ self.embed_dim = config.embed_dim
+ self.config = config
+ self.proj = nn.Conv2d(
+ config.num_channels,
+ config.embed_dim,
+ kernel_size=(config.patch_size, config.patch_size),
+ stride=(config.patch_size, config.patch_size),
+ )
+ self.norm = RMSNorm(config.embed_dim, eps=config.rms_norm_eps)
+
+ def forward(self, x: torch.Tensor, grid_thw=None) -> torch.Tensor:
+ x = x.view(-1, self.num_channels, self.temporal_patch_size, self.patch_size, self.patch_size)[:, :, 0]
+ x = self.proj(x).view(-1, self.embed_dim)
+ x = self.norm(x)
+ return x
+
+
+class DotsViTPreprocessor(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.patch_h = config.patch_size
+ self.patch_w = config.patch_size
+ self.embed_dim = config.embed_dim
+ self.config = config
+ self.patchifier = DotsPatchEmbed(config)
+
+ def forward(self, x: torch.Tensor, grid_thw=None) -> torch.Tensor:
+ tokens = self.patchifier(x, grid_thw)
+ return tokens
+
+
+class DotsVisionBlock(nn.Module):
+ def __init__(self, config, attn_implementation: str = "flash_attention_2"):
+ super().__init__()
+ self.attn = DOTS_VISION_ATTENTION_CLASSES[attn_implementation](
+ config, config.embed_dim, num_heads=config.num_attention_heads, bias=config.use_bias
+ )
+ self.norm1 = RMSNorm(config.embed_dim, eps=config.rms_norm_eps)
+ self.mlp = DotsSwiGLUFFN(config)
+ self.norm2 = RMSNorm(config.embed_dim, eps=config.rms_norm_eps)
+
+ def forward(self, hidden_states, cu_seqlens, rotary_pos_emb) -> torch.Tensor:
+ hidden_states = hidden_states + self.attn(
+ self.norm1(hidden_states), cu_seqlens=cu_seqlens, rotary_pos_emb=rotary_pos_emb
+ )
+ hidden_states = hidden_states + self.mlp(self.norm2(hidden_states))
+ return hidden_states
+
+
+class DotsVisionTransformer(PreTrainedModel):
+ def __init__(self, config: DotsVisionConfig) -> None:
+ super().__init__(config)
+ self.config = config
+ self.spatial_merge_size = config.spatial_merge_size
+
+ self.patch_embed = DotsViTPreprocessor(config)
+ self._init_weights(self.patch_embed.patchifier.proj)
+
+ head_dim = config.embed_dim // config.num_attention_heads
+
+ self.rotary_pos_emb = VisionRotaryEmbedding(head_dim // 2)
+
+ _num_hidden_layers = config.num_hidden_layers
+ self.blocks = nn.ModuleList(
+ [DotsVisionBlock(config, config.attn_implementation) for _ in range(_num_hidden_layers)]
+ )
+
+ if self.config.post_norm:
+ self.post_trunk_norm = RMSNorm(config.embed_dim, eps=config.rms_norm_eps)
+
+ self.merger = PatchMerger(
+ dim=config.hidden_size,
+ context_dim=config.embed_dim,
+ spatial_merge_size=config.spatial_merge_size,
+ init_merger_std=self.config.init_merger_std,
+ )
+
+ self.gradient_checkpointing = False
+ self._gradient_checkpointing_func = torch.utils.checkpoint.checkpoint
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, (nn.Linear, nn.Conv3d)):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+ @property
+ def dtype(self) -> torch.dtype:
+ return self.blocks[0].mlp.fc2.weight.dtype
+
+ @property
+ def device(self) -> torch.device:
+ return self.blocks[0].mlp.fc2.weight.device
+
+ def get_pos_ids_by_grid(self, grid_thw):
+ pos_ids = []
+ for t, h, w in grid_thw:
+ hpos_ids = torch.arange(h).unsqueeze(1).expand(-1, w)
+ hpos_ids = hpos_ids.reshape(
+ h // self.spatial_merge_size,
+ self.spatial_merge_size,
+ w // self.spatial_merge_size,
+ self.spatial_merge_size,
+ )
+ hpos_ids = hpos_ids.permute(0, 2, 1, 3)
+ hpos_ids = hpos_ids.flatten()
+
+ wpos_ids = torch.arange(w).unsqueeze(0).expand(h, -1)
+ wpos_ids = wpos_ids.reshape(
+ h // self.spatial_merge_size,
+ self.spatial_merge_size,
+ w // self.spatial_merge_size,
+ self.spatial_merge_size,
+ )
+ wpos_ids = wpos_ids.permute(0, 2, 1, 3)
+ wpos_ids = wpos_ids.flatten()
+ pos_ids.append(
+ torch.stack([hpos_ids, wpos_ids], dim=-1).repeat(t, 1)
+ )
+
+ return pos_ids
+
+ def rot_pos_emb(self, grid_thw):
+ pos_ids = self.get_pos_ids_by_grid(grid_thw)
+ pos_ids = torch.cat(pos_ids, dim=0)
+ max_grid_size = grid_thw[:, 1:].max()
+ rotary_pos_emb_full = self.rotary_pos_emb(max_grid_size)
+ rotary_pos_emb = rotary_pos_emb_full[pos_ids].flatten(1)
+ return rotary_pos_emb
+
+ def forward(self, hidden_states: torch.Tensor, grid_thw: torch.Tensor, bf16=True) -> torch.Tensor:
+ if bf16:
+ hidden_states = hidden_states.bfloat16()
+ hidden_states = self.patch_embed(hidden_states, grid_thw)
+
+ rotary_pos_emb = self.rot_pos_emb(grid_thw)
+
+ cu_seqlens = torch.repeat_interleave(grid_thw[:, 1] * grid_thw[:, 2], grid_thw[:, 0]).cumsum(
+ dim=0,
+ dtype=grid_thw.dtype if torch.jit.is_tracing() else torch.int32,
+ )
+ cu_seqlens = F.pad(cu_seqlens, (1, 0), value=0)
+
+ for blk in self.blocks:
+ if self.gradient_checkpointing and self.training:
+ hidden_states = self._gradient_checkpointing_func(
+ blk.__call__,
+ hidden_states,
+ cu_seqlens,
+ rotary_pos_emb,
+ use_reentrant=(self.config.ckpt_use_reentrant or self.config.ve_ckpt_use_reentrant),
+ )
+ else:
+ hidden_states = blk(hidden_states, cu_seqlens=cu_seqlens, rotary_pos_emb=rotary_pos_emb)
+
+ if self.config.post_norm:
+ hidden_states = self.post_trunk_norm(hidden_states)
+
+ hidden_states = self.merger(hidden_states)
+ return hidden_states
\ No newline at end of file
diff --git a/preprocessor_config.json b/preprocessor_config.json
new file mode 100644
index 0000000..5786e21
--- /dev/null
+++ b/preprocessor_config.json
@@ -0,0 +1,19 @@
+{
+ "min_pixels": 3136,
+ "max_pixels": 11289600,
+ "patch_size": 14,
+ "temporal_patch_size": 1,
+ "merge_size": 2,
+ "image_mean": [
+ 0.48145466,
+ 0.4578275,
+ 0.40821073
+ ],
+ "image_std": [
+ 0.26862954,
+ 0.26130258,
+ 0.27577711
+ ],
+ "image_processor_type": "Qwen2VLImageProcessor",
+ "processor_class": "DotsVLProcessor"
+}
diff --git a/special_tokens_map.json b/special_tokens_map.json
new file mode 100644
index 0000000..ec36c2f
--- /dev/null
+++ b/special_tokens_map.json
@@ -0,0 +1,25 @@
+{
+ "additional_special_tokens": [
+ "<|im_start|>",
+ "<|im_end|>",
+ "<|object_ref_start|>",
+ "<|object_ref_end|>",
+ "<|box_start|>",
+ "<|box_end|>",
+ "<|quad_start|>",
+ "<|quad_end|>",
+ "<|vision_start|>",
+ "<|vision_end|>",
+ "<|vision_pad|>",
+ "<|image_pad|>",
+ "<|video_pad|>"
+ ],
+ "eos_token": {
+ "content": "<|endoftext|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false
+ },
+ "pad_token": "[PAD]"
+}
diff --git a/tokenizer.json b/tokenizer.json
new file mode 100644
index 0000000..2a7818e
--- /dev/null
+++ b/tokenizer.json
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:386545eb05f08c51352cde2fcc2c867f1592bb330f305efd1c6a57a93b1244cd
+size 7036028
diff --git a/tokenizer_config.json b/tokenizer_config.json
new file mode 100644
index 0000000..a7055e5
--- /dev/null
+++ b/tokenizer_config.json
@@ -0,0 +1,391 @@
+{
+ "add_bos_token": false,
+ "add_prefix_space": false,
+ "added_tokens_decoder": {
+ "151643": {
+ "content": "<|endoftext|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151644": {
+ "content": "<|im_start|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151645": {
+ "content": "<|im_end|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151646": {
+ "content": "<|object_ref_start|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151647": {
+ "content": "<|object_ref_end|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151648": {
+ "content": "<|box_start|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151649": {
+ "content": "<|box_end|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151650": {
+ "content": "<|quad_start|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151651": {
+ "content": "<|quad_end|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151652": {
+ "content": "<|vision_start|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151653": {
+ "content": "<|vision_end|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151654": {
+ "content": "<|vision_pad|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151655": {
+ "content": "<|image_pad|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151656": {
+ "content": "<|video_pad|>",
+ "lstrip": false,
+ "normalized": false,
+ "rstrip": false,
+ "single_word": false,
+ "special": true
+ },
+ "151657": {
+ "content": "