5.3 KiB
5.3 KiB
| frameworks | license | tasks | ||
|---|---|---|---|---|
|
Apache License 2.0 |
|
当前模型的贡献者未提供更加详细的模型介绍。模型文件和权重,可浏览“模型文件”页面获取。
您可以通过如下git clone命令,或者ModelScope SDK来下载模型
Highlights
- SenseVoice-Small模型支持中、粤、英、日、韩多语言语音识别,在中、粤识别效果上明显优于Whisper模型。
- SenseVoice-Small模型具备优秀的情感识别,能够在测试数据上达到和超过目前最佳情感识别模型的效果。
- SenseVoice-Small模型支持声音事件检测能力,支持音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事件进行检测。
- SenseVoice-Small采用非自回归端到端框架,推理延迟极低,10s音频推理仅耗时70ms。
- SenseVoice支持模型微调和onnx服务部署。
SenseVoice开源项目介绍
SenseVoice开源模型是多语言音频理解模型,具有包括语音识别、语种识别、语音情感识别,声学事件检测能力。
FunASR开源项目介绍
FunASR希望在语音识别的学术研究和工业应用之间架起一座桥梁。通过发布工业级语音识别模型的训练和微调,研究人员和开发人员可以更方便地进行语音识别模型的研究和生产,并推动语音识别生态的发展。让语音识别更有趣!
github仓库 | 最新动态 | 环境安装 | 服务部署 | 模型库 | 联系我们
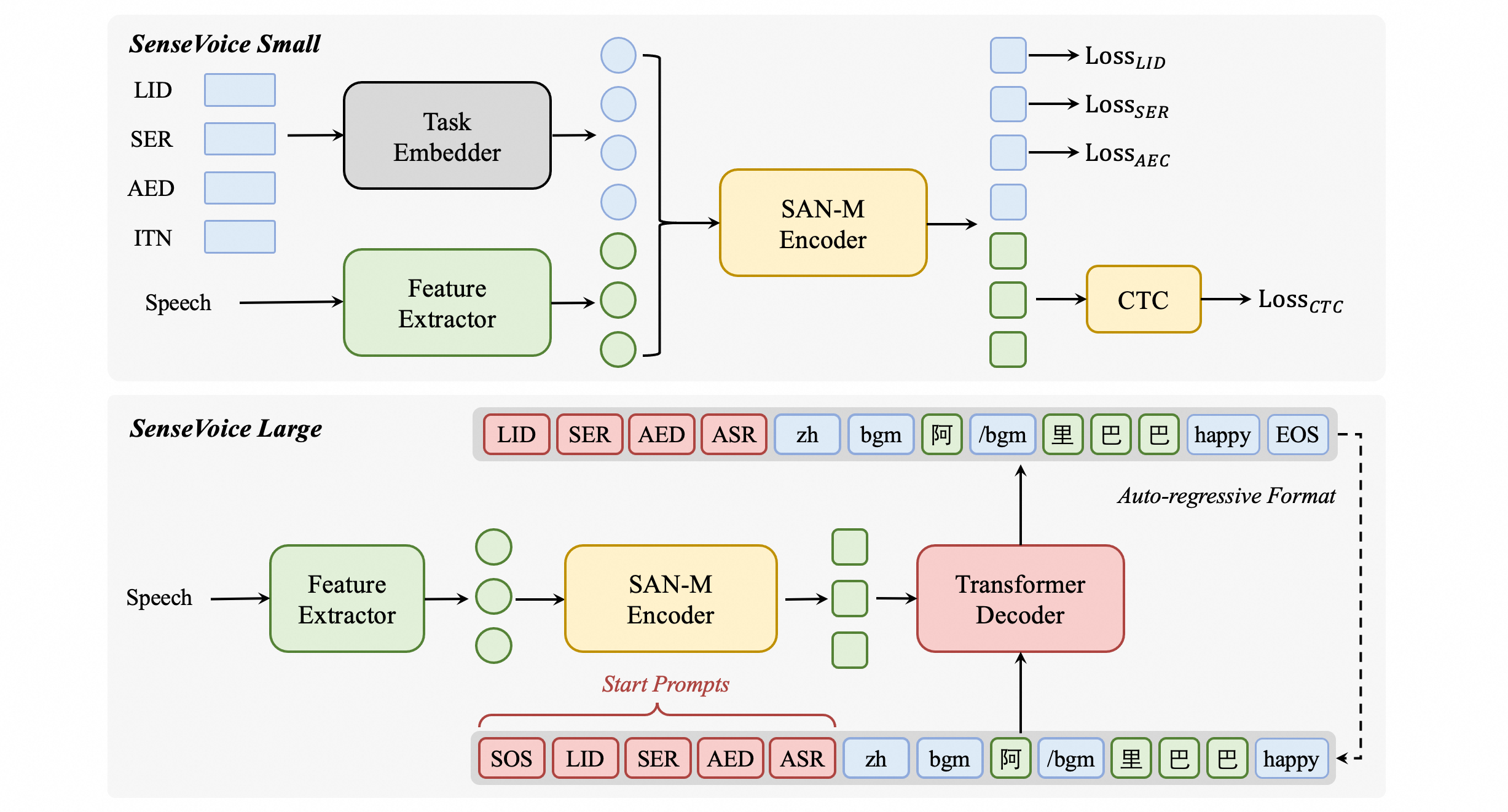
模型结构图
SenseVoice多语言音频理解模型,支持语音识别、语种识别、语音情感识别、声学事件检测、逆文本正则化等能力,采用工业级数十万小时的标注音频进行模型训练,保证了模型的通用识别效果。模型可以被应用于中文、粤语、英语、日语、韩语音频识别,并输出带有情感和事件的富文本转写结果。
用法
用法
推理
直接推理
from model import SenseVoiceSmall
model_dir = "iic/SenseVoiceSmall"
m, kwargs = SenseVoiceSmall.from_pretrained(model=model_dir)
res = m.inference(
data_in="https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav",
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=False,
**kwargs,
)
print(res)
使用funasr推理
from funasr import AutoModel
model_dir = "iic/SenseVoiceSmall"
input_file = (
"https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav"
)
model = AutoModel(model=model_dir,
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
trust_remote_code=True, device="cuda:0")
res = model.generate(
input=input_file,
cache={},
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=False,
batch_size_s=0,
)
print(res)
funasr版本已经集成了vad模型,支持任意时长音频输入,batch_size_s单位为秒。
如果输入均为短音频,并且需要批量化推理,为了加快推理效率,可以移除vad模型,并设置batch_size
model = AutoModel(model=model_dir, trust_remote_code=True, device="cuda:0")
res = model.generate(
input=input_file,
cache={},
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=False,
batch_size=64,
)
更多详细用法,请参考 文档
模型下载
SDK下载
#安装ModelScope
pip install modelscope
#SDK模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('iic/SenseVoiceSmall')
Git下载
#Git模型下载
git clone https://www.modelscope.cn/iic/SenseVoiceSmall.git
服务部署
Undo
如果您是本模型的贡献者,我们邀请您根据模型贡献文档,及时完善模型卡片内容。